
Нечеткая логика примеры из жизни. Обзор программного обеспечения на основе нечеткой логики
Нечеткая логика (fuzzy logic )возникла как наиболее удобный способ построения сложными технологическими процессами, а также нашла применение в бытовой электронике, диагностических и других экспертных системах. Математический аппарат нечеткой логики впервые был разработан в США в середине 60-х годов прошлого века, активное развитие данного метода началось и в Европе.
Классическая логика развивается с древнейших времен. Ее основоположником считается Аристотель. Логика известна нам как строгая наука, имеющая множество прикладных применений: например, именно на положениях классической (булевой) логики основан принцип действия всех современных компьютеров. Вместе с тем классическая логика имеет один существенный недостаток - с ее помощью невозможно адекватно описать ассоциативное мышление человека. Классическая логика оперирует только двумя понятиями: ИСТИНА и ЛОЖЬ (логические 1 или 0), и исключая любые промежуточные значения. Все это хорошо для вычислительных машин, но попробуйте представить весь окружающий вас мир только в черном и белом цвете, вдобавок исключив из языка любые ответы на вопросы, кроме ДА и НЕТ. В такой ситуации вам можно только посочувствовать.
Традиционная математика с ее точными и однозначными формулировками закономерностей также имеет в своей основе классическую логику. А поскольку именно математика, в свою очередь, представляет собой универсальный инструмент для описания явлений окружающего мира во всех естественных науках (физика, химия, биология и т. д.) и их прикладных приложениях (например, теория измерений, теория управления и т. д.), неудивительно все эти науки оперируют математически точными данными, такими как: «средняя скорость автомобиля на участке пути длиной 62 км равнялась 93 км/ч». Но мыслит ли в действительности человек такими категориями? Представим, что в вашей машине вышел из строя спидометр. Означает ли это, что отныне вы лишены возможности оценивать скорость вашего перемещения и не в состоянии ответить на вопросы типа «быстро ли ты доехал вчера домой?». Разумеется нет. Скорее всего вы скажете в ответ что-то вводе: «Да, довольно быстро». Собственно говоря, вы скорее всего ответите примерно в том же духе, даже и в том случае, если спидометр вашей машины был в полном порядке, поскольку, совершая поездки, не имеете привычки непрерывно отслеживать его показания в режиме реального времени. То есть, в своем естественном мышлении применительно к скорости мы склонны оперировать не точными значениями в км/ч или м/с, а приблизительными оценками типа: «медленно», «средне», «быстро» и бесчисленным множеством полутонов и промежуточных оценок: «тащился как черепаха», «катился, не торопясь», «не выбивался из потока», «ехал довольно быстро», «несся как ненормальный» и т. п.
Если попытаться выразить наши интуитивные понятия о скорости графически, то получится нечто вроде рисунка ниже.
Здесь по оси X отложены значения скорости в традиционной строгой математической записи, а по оси Y – т. н. функцию принадлежности (изменяется от 0 до 1) точного значения скорости к нечеткому множеству , обозначенному тем или иным значением лингвистической переменной «скорость»: очень низкая, низкая, средняя, высокая и очень высокая. Этих градаций (гранул) может быть меньше или больше. Чем больше гранулированность нечеткой информации, тем больше она приближается к математически точной оценке (не забудем, что и выраженная в традиционной форме измерительная информация всегда обладает некоторой погрешностью, а значит в определенном смысле также является нечеткой). Таким образом, например значение скорости 105 км/ч принадлежит к нечеткому множеству «высокая» со значением функции принадлежности 0.8, а к множеству «очень высокая» со значением 0.5.
Другой пример – оценка возраста человека. Часто мы не имеем абсолютно точной информации о возрасте того или иного знакомого нам человека и поэтому, отвечая на соответствующий вопрос, вынуждены давать нечеткую оценку типа: «ему лет 30» или «ему далеко за 60» и т. п. Особенно часто используются такие значения лингвистической переменной «возраст» как: «молодой», «средних лет», «старый» и т. п. На рисунке ниже приведен графически возможный вид нечеткого множества «возраст = молодой» (очевидно, с точки зрения человека, которому самому ну никак не больше 20 лет;)
Нечеткие числа, получаемые в результате “не вполне точных измерений”, во многом похожи (но не тождественны! см. пример с двумя бутылками) распределениям теории вероятностей, но свободны от присущих последним недостатков: малое количество пригодных к анализу функций распределения, необходимость их принудительной нормализации, соблюдение требований аддитивности, трудность обоснования адекватности математической абстракции для описания поведения фактических величин. По сравнению с точными и, тем более, вероятностными методами, нечеткие методы измерения и управления позволяют резко сократить объем производимых вычислений, что, в свою очередь, приводит к увеличению быстродействия нечетких систем.
Как уже говорилось, принадлежность каждого точного значения к одному из значений лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным. Сейчас сформировалось понятие о так называемых стандартных функциях принадлежности (см. рисунок ниже).

Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Процесс построения (графического или аналитического) функции принадлежности точных значений к нечеткому множеству называется фаззификацией данных.
Нечёткая логика – логика, основанная на теории нечётких множеств. Её предметом является построение моделей приближенных рассуждений человека и использование их в компьютерных системах. В нечёткой логике расширена граница оценки с двузначной (Либо 0, либо 1) до неограниченной многозначной оценки (На интервале ).
Нечёткое множество A в полном пространстве X определяется через функцию принадлежности m A (x):

Логика определения понятия нечёткого множества не содержит какой-либо нечёткости. Вместо указания какого-то конкретного значения (Например 0.8) обычно с помощью нижних и верхних значений задают допустимые пределы оценки (Например ).
В случае нечёткой логики можно создать неограниченное число операций, поэтому в ней не используются базовые операции для записи остальных. Особо важное значение имеют расширения НЕ, И, ИЛИ до нечётких операций. Они называются соответственно – нечёткое отрицание, t-норма и s-норма. Так как число состояний неограниченно, то невозможно описать эти операции с помощью таблицы истинности. Операции поясняются с помощью функций и аксиом, а представляются с помощью графиков.
Аксиоматическое представление нечётких операций:
Нечёткое отрицание

Аксиома N1 сохраняет свойство двузначного НЕ, а N2 – сохраняет правило двойного отрицания. N3 – наиболее существенная: нечёткое отрицание инвертирует последовательность оценок.

Типичная операция нечёткого отрицания – вычитание из 1.
При отрицании значение 0.5 является центральным и обычно x и x θ принимают симметричные значения относительно 0.5.
T-норма.

Аксиома T1 справедлива, как и для чёткого И. T2 и T3 – законы пересечения и объединения. Аксиома T4 является требованием упорядоченности.
Типичной t-нормой является операция min или логическое произведение:

При логическом произведении график строится симметрично относительно плоскости, образуемый наклонными x1 и x2.
S-норма.

Типичной s-нормой является логическая сумма, определяемая операцией max.
![]()
Кроме неё существуют алгебраическая сумма, граничная сумма и драстическая сумма:


Как видно из рисунков порядок обратный, нежели в случае t-нормы.
В качестве примеров нечёткого определения можно рассмотреть температуру и работу клапана:

Сходства
Нечёткая логика является обобщением классической чёткой логики. И чёткая и нечёткая логики основаны на множествах и на операциях отношения. Нечёткие операции являются расширением операций чёткой логики.
Различия
В чёткой логике переменные являются полными членными множеств, а в нечёткой – только частичными членами множеств.
В чёткой логике утверждение либо истинно, либо ложно, в ней действует закон исключения среднего. В нечёткой логике истинность или ложность перестают быть абсолютными и утверждения могут быть частично истинными и частично ложными. В чёткой логике число возможных операций конечно и зависит от количества входов, тогда как в нечёткой логике число возможных операций бесконечно.
3. Пример
Сначала мы рассмотрим множество X всех вещественных чисел между 0 и 10, которые мы назовем областью исследования. Теперь, давайте определим подмножество X всех вещественных чисел в амплитуде между 5 и 8.
A =
Теперь представим множество A с помощью символической функции, т.е. эта функция приписывает число 1 или 0 к каждому элементу в X , в зависимости от того, находится ли элемент в подмножестве А или нет. Это приводит к следующей диаграмме:

Мы можем интерпретировать элементы, которым назначено число 1, как элементы которые находятся в множестве А, и элементы, которым назначено число 0, как элементы не в множестве A .
Этой концепции достаточно для многих областей приложений. Но мы можем легко найти ситуации, где теряется гибкость. Чтобы показать это рассмотрим следующий пример, показывающий отличие нечёткого множества от чёткого:
В этом примере мы хотим описать множество молодых людей. Более формально мы можем обозначить
B = {множество молодых людей}
Поскольку, вообще, возраст начинается с 0, нижняя граница этого множества должна быть нулевой. Верхнюю границу, с другой стороны, надо определить. На первый раз определим верхнюю границу множества, скажем, 20 лет. Следовательно, мы получаем B как четкий интервал, а именно:
B =
Теперь возникает вопрос: почему кто-то на его 20-ом дне рождения молодой, а на следующий день не молодой? Очевидно, это - структурная проблема, поскольку, если мы перемещаем верхнюю границу от 20 до произвольной точки, мы можем излагать тот же самый вопрос.
Более естественный способ описать множество B состоит в том, чтобы ослабить строгое разделение между молодыми и не молодыми. Мы будем делать это, допуская не только (четкое) решение ДА: он/она находится в множестве молодых , или НЕТ: он/она не в множестве молодых , но более гибких фраз подобно: Хорошо, он/она принадлежит немного больше к множеству молодых или НЕТ, он/она почти не принадлежит к множеству молодых.
В нашем первом примере мы кодировали все элементы Области Исследования 0 или 1. Прямой путь обобщить эту концепцию для нечёткого множества состоит в том, чтобы определить большее количество значений между 0 и 1. Фактически, мы определяем бесконечно многие варианты между 0 и 1, а именно единичный интервал I = .
Интерпретация чисел в нечётком множестве, назначенная всем элементам Области Исследования, более трудная. Конечно, снова число 1 назначено элементу как способ определить элемент, который находится в множестве B и 0 - способ, при котором элемент не определен в множестве B . Все другие значения означают постепенную принадлежность к множеству B .
Для большей наглядности, теперь мы показываем множество молодых, подобно нашему первому примеру, графически при помощи символической функции.

При таком способе 25-летние люди будут все еще молоды на 50 процентов (0.5). Теперь Вы знаете, что такое нечеткое множество.
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) являются обобщениями классической теории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких и приближенных рассуждений при описании человеком процессов, систем, объектов.
Прежде чем нечеткий подход к моделированию сложных систем получил признание во всем мире, прошло не одно десятилетие с момента зарождения теории нечетких множеств. И на этом пути развития нечетких систем принято выделять три периода.
Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э. Мамдани, Беллман). Во втором периоде (70–80-е годы) появляются первые практические результаты в области нечеткого управления сложными техническими системами (парогенератор с нечетким управлением). Одновременно стало уделяться внимание вопросам построения экспертных систем, построенных на нечеткой логике, разработке нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других.
Триумфальное шествие нечеткой логики по миру началось после доказательства в конце 80-х Бартоломеем Коско знаменитой теоремы FAT (Fuzzy Approximation Theorem). В бизнесе и финансах нечеткая логика получила признание после того как в 1988 году экспертная система на основе нечетких правил для прогнозирования финансовых индикаторов единственная предсказала биржевой крах. И количество успешных фаззи-применений в настоящее время исчисляется тысячами.
Математический аппарат
Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF c (x) – степень принадлежности к нечеткому множеству C, представляющей собой обобщение понятия характеристической функции обычного множества. Тогда нечетким множеством С называется множество упорядоченных пар вида C={MF c (x)/x}, MF c (x) . Значение MF c (x)=0 означает отсутствие принадлежности к множеству, 1 – полную принадлежность.
Проиллюстрируем это на простом примере. Формализуем неточное определение "горячий чай". В качестве x (область рассуждений) будет выступать шкала температуры в градусах Цельсия. Очевидно, что она будет изменяется от 0 до 100 градусов. Нечеткое множество для понятия "горячий чай" может выглядеть следующим образом:
C={0/0; 0/10; 0/20; 0,15/30; 0,30/40; 0,60/50; 0,80/60; 0,90/70; 1/80; 1/90; 1/100}.
Так, чай с температурой 60 С принадлежит к множеству "Горячий" со степенью принадлежности 0,80. Для одного человека чай при температуре 60 С может оказаться горячим, для другого – не слишком горячим. Именно в этом и проявляется нечеткость задания соответствующего множества.
Для нечетких множеств, как и для обычных, определены основные логические операции. Самыми основными, необходимыми для расчетов, являются пересечение и объединение.
Пересечение двух нечетких множеств (нечеткое "И"): A B: MF AB (x)=min(MF A (x), MF B (x)).
Объединение двух нечетких множеств (нечеткое "ИЛИ"): A B: MF AB (x)=max(MF A (x), MF B (x)).
В теории нечетких множеств разработан общий подход к выполнению операторов пересечения, объединения и дополнения, реализованный в так называемых треугольных нормах и конормах. Приведенные выше реализации операций пересечения и объединения – наиболее распространенные случаи t-нормы и t-конормы.
Для описания нечетких множеств вводятся понятия нечеткой и лингвистической переменных.
Нечеткая переменная описывается набором (N,X,A), где N – это название переменной, X – универсальное множество (область рассуждений), A – нечеткое множество на X.
Значениями лингвистической переменной могут быть нечеткие переменные, т.е. лингвистическая переменная находится на более высоком уровне, чем нечеткая переменная. Каждая лингвистическая переменная состоит из:
- названия;
- множества своих значений, которое также называется базовым терм-множеством T. Элементы базового терм-множества представляют собой названия нечетких переменных;
- универсального множества X;
- синтаксического правила G, по которому генерируются новые термы с применением слов естественного или формального языка;
- семантического правила P, которое каждому значению лингвистической переменной ставит в соответствие нечеткое подмножество множества X.
Рассмотрим такое нечеткое понятие как "Цена акции". Это и есть название лингвистической переменной. Сформируем для нее базовое терм-множество, которое будет состоять из трех нечетких переменных: "Низкая", "Умеренная", "Высокая" и зададим область рассуждений в виде X= (единиц). Последнее, что осталось сделать – построить функции принадлежности для каждого лингвистического терма из базового терм-множества T.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:
$$MF\,(x) = \,\begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac{x\,-\,b}{c\,-\,b},\,b\leq \,x\leq \,c &\ \\ 0, \;x\,\not \in\,(a;\,c)\ \end{cases}$$
При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):
$$MF\,(x)\,=\, \begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac{x\,-\,c}{d\,-\,c},\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end{cases}$$
При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
Функция принадлежности гауссова типа описывается формулой
$$MF\,(x) = \exp\biggl[ -\,{\Bigl(\frac{x\,-\,c}{\sigma}\Bigr)}^2\biggr]$$
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.

Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке 3 приведен пример описанной выше лингвистической переменной "Цена акции", на рисунке 4 – формализация неточного понятия "Возраст человека". Так, для человека 48 лет степень принадлежности к множеству "Молодой" равна 0, "Средний" – 0,47, "Выше среднего" – 0,20.
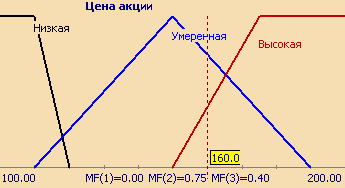

Количество термов в лингвистической переменной редко превышает 7.
Нечеткий логический вывод
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
- Существует хотя бы одно правило для каждого лингвистического терма выходной переменной.
- Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида:
R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1
…
R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i
…
R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m ,
где x k , k=1..n – входные переменные; y – выходная переменная; A ik – заданные нечеткие множества с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).

Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
- Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
$$alfa_i\,=\,\min_i \,(A_{ik}\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
где MF(y) – функция принадлежности итогового нечеткого множества.
Дефазификация, или приведение к четкости. Существует несколько методов дефазификации. Например, метод среднего центра, или центроидный метод:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
Геометрический смысл такого значения – центр тяжести для кривой MF(y). Рисунок 6 графически показывает процесс нечеткого вывода по Мамдани для двух входных переменных и двух нечетких правил R1 и R2.

Интеграция с интеллектуальными парадигмами
Гибридизация методов интеллектуальной обработки информации – девиз, под которым прошли 90-е годы у западных и американских исследователей. В результате объединения нескольких технологий искусственного интеллекта появился специальный термин – "мягкие вычисления" (soft computing), который ввел Л. Заде в 1994 году. В настоящее время мягкие вычисления объединяют такие области как: нечеткая логика, искусственные нейронные сети, вероятностные рассуждения и эволюционные алгоритмы. Они дополняют друг друга и используются в различных комбинациях для создания гибридных интеллектуальных систем.
Влияние нечеткой логики оказалось, пожалуй, самым обширным. Подобно тому, как нечеткие множества расширили рамки классической математическую теорию множеств, нечеткая логика "вторглась" практически в большинство методов Data Mining, наделив их новой функциональностью. Ниже приводятся наиболее интересные примеры таких объединений.
Нечеткие нейронные сети
Нечеткие нейронные сети (fuzzy-neural networks) осуществляют выводы на основе аппарата нечеткой логики, однако параметры функций принадлежности настраиваются с использованием алгоритмов обучения НС. Поэтому для подбора параметров таких сетей применим метод обратного распространения ошибки, изначально предложенный для обучения многослойного персептрона. Для этого модуль нечеткого управления представляется в форме многослойной сети. Нечеткая нейронная сеть как правило состоит из четырех слоев: слоя фазификации входных переменных, слоя агрегирования значений активации условия, слоя агрегирования нечетких правил и выходного слоя.
Наибольшее распространение в настоящее время получили архитектуры нечеткой НС вида ANFIS и TSK. Доказано, что такие сети являются универсальными аппроксиматорами.
Быстрые алгоритмы обучения и интерпретируемость накопленных знаний – эти факторы сделали сегодня нечеткие нейронные сети одним из самых перспективных и эффективных инструментов мягких вычислений.
Адаптивные нечеткие системы
Классические нечеткие системы обладают тем недостатком, что для формулирования правил и функций принадлежности необходимо привлекать экспертов той или иной предметной области, что не всегда удается обеспечить. Адаптивные нечеткие системы (adaptive fuzzy systems) решают эту проблему. В таких системах подбор параметров нечеткой системы производится в процессе обучения на экспериментальных данных. Алгоритмы обучения адаптивных нечетких систем относительно трудоемки и сложны по сравнению с алгоритмами обучения нейронных сетей, и, как правило, состоят из двух стадий: 1. Генерация лингвистических правил; 2. Корректировка функций принадлежности. Первая задача относится к задаче переборного типа, вторая – к оптимизации в непрерывных пространствах. При этом возникает определенное противоречие: для генерации нечетких правил необходимы функции принадлежности, а для проведения нечеткого вывода – правила. Кроме того, при автоматической генерации нечетких правил необходимо обеспечить их полноту и непротиворечивость.
Значительная часть методов обучения нечетких систем использует генетические алгоритмы. В англоязычной литературе этому соответствует специальный термин – Genetic Fuzzy Systems.
Значительный вклад в развитие теории и практики нечетких систем с эволюционной адаптацией внесла группа испанских исследователей во главе с Ф. Херрера (F. Herrera).
Нечеткие запросы
Нечеткие запросы к базам данных (fuzzy queries) – перспективное направление в современных системах обработки информации. Данный инструмент дает возможность формулировать запросы на естественном языке, например: "Вывести список недорогих предложений о съеме жилья близко к центру города", что невозможно при использовании стандартного механизма запросов. Для этой цели разработана нечеткая реляционная алгебра и специальные расширения языков SQL для нечетких запросов. Большая часть исследований в этой области принадлежит западноевропейским ученым Д. Дюбуа и Г. Праде.
Нечеткие ассоциативные правила
Нечеткие ассоциативные правила (fuzzy associative rules) – инструмент для извлечения из баз данных закономерностей, которые формулируются в виде лингвистических высказываний. Здесь введены специальные понятия нечеткой транзакции, поддержки и достоверности нечеткого ассоциативного правила.
Нечеткие когнитивные карты
Нечеткие когнитивные карты (fuzzy cognitive maps) были предложены Б. Коско в 1986 г. и используются для моделирования причинных взаимосвязей, выявленных между концептами некоторой области. В отличие от простых когнитивных карт, нечеткие когнитивные карты представляют собой нечеткий ориентированный граф, узлы которого являются нечеткими множествами. Направленные ребра графа не только отражают причинно-следственные связи между концептами, но и определяют степень влияния (вес) связываемых концептов. Активное использование нечетких когнитивных карт в качестве средства моделирования систем обусловлено возможностью наглядного представления анализируемой системы и легкостью интерпретации причинно-следственных связей между концептами. Основные проблемы связаны с процессом построения когнитивной карты, который не поддается формализации. Кроме того, необходимо доказать, что построенная когнитивная карта адекватна реальной моделируемой системе. Для решения данных проблем разработаны алгоритмы автоматического построения когнитивных карт на основе выборки данных.
Нечеткая кластеризация
Нечеткие методы кластеризации, в отличие от четких методов (например, нейронные сети Кохонена), позволяют одному и тому же объекту принадлежать одновременно нескольким кластерам, но с различной степенью. Нечеткая кластеризация во многих ситуациях более "естественна", чем четкая, например, для объектов, расположенных на границе кластеров. Наиболее распространены: алгоритм нечеткой самоорганизации c-means и его обобщение в виде алгоритма Густафсона-Кесселя.
Литература
- Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. – М.: Мир, 1976.
- Круглов В.В., Дли М.И. Интеллектуальные информационные системы: компьютерная поддержка систем нечеткой логики и нечеткого вывода. – М.: Физматлит, 2002.
- Леоленков А.В. Нечеткое моделирование в среде MATLAB и fuzzyTECH. – СПб., 2003.
- Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. – М., 2004.
- Масалович А. Нечеткая логика в бизнесе и финансах. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Fuzzy systems as universal approximators // IEEE Transactions on Computers, vol. 43, No. 11, November 1994. – P. 1329-1333.
- Cordon O., Herrera F., A General study on genetic fuzzy systems // Genetic Algorithms in engineering and computer science, 1995. – P. 33-57.
6 сентября 2017 в возрасте 96 лет умер Лотфи Заде, создатель нечеткой логики.
6 сентября 2017 в компании, которая основана на технологиях нечеткой логики и нейронных сетей, и в которой я пока работаю, начались такие преобразования, которые только в рамках этой самой нечеткой логики и можно как-нибудь описать. И с завтрашнего дня будет расторгнут мой контракт, хотя если с 15 сентября я и становлюсь безработным, то это можно будет оценить только в терминах нечетной логики - на 0,28, на 0,78 или 1,58 - жизнь покажет.
А два года назад, к 50-летию нечеткой логики, Александр Малютин написал заметку на научпоп-сайт «Перельман перезвонит» (nowwow.info). Сайт этот ныне уже умер, и поэтому следует спасти статью. Ведь про нечетную логику написал журналист, который в свое время возглавлял «Известия». Кстати, блогеры-домохозяйки могут не выходить - нечетная логика объясняется на примере стиральной машины. Лучше поучитесь у профи, как надо писать.
К 50-ЛЕТИЮ ОДНОГО ИЗ САМЫХ УДАЧНЫХ МАТЕМАТИЧЕСКИХ ТЕРМИНОВ
Нечеткой логике полвека - в июне 1965 года в журнале Information and Control вышла основополагающая статья «Нечеткие множества» (Fuzzy Sets), которую написал американский математик азербайджанского происхождения Лотфи Заде. Долгих ему лет. Жаль, до юбилея не дожил британский математик танзанийского происхождения Ибрагим Мамдани, который в 1975 году представил первую реальную систему управления с нечеткой логикой - контроллер, следящий за работой парового двигателя. После чего технология стала активно развиваться, найдя применение во многих областях.
Заде 50 лет назад предложил математическое описание живой человеческой логики. В обычной математической логике есть только «истина» (обозначаемая еще числом 1) или «ложь» (0). В нечеткой логике степень истинности высказывания может быть любой - точнее, любым числом от 0 до 1. Красива ли вон та девушка? Ни да, ни нет, а «0,78; что красива».
Непривычно звучит. Как это вообще понять? Для простоты можно считать, что кто-то провел опрос, в котором 78% респондентов назвали девушку красивой, а остальные нет. А может ли быть от таких конструкций практическая польза? Вполне. Допустим, нужно принять решение, отправлять ли девушку на конкурс мисс чего-нибудь (серьезные расходы!), а для этого нужно оценить ее шансы на призовое место. Тогда-то и пригодятся оценки не только красоты, но и других важных для победы и тоже нечетких параметров: остроумия, эрудированности, доброты и т. п. Нужно только понять, откуда брать степени истинности и как оперировать с нечеткими данными. Заде понял. Необходимый для практики математический аппарат он разработал к 1973 году. Мамдани на его основе и сделал свой контроллер.
Заслуга Лотфи Заде не только в том, что он разработал новую теорию. Он ее крайне удачно назвал, выбрав общеупотребительное слово. Если бы вместо «нечеткой» взяли заумный термин, например, «континуальнозначная логика» (что, кстати, так и есть), у него не было бы шансов на широкую известность. Неспециалисты просто не употребляли бы это словосочетание, поскольку кто ж его знает, что оно означает.
Другое дело, когда у научного понятия есть бытовой омоним. Тогда обывателю кажется, что он понимает, о чем речь, особенно если посмотрел про это кино. Таких «понятных» терминов в математике и физике тоже немало. Черная дыра. Магический квадрат. Горизонт событий. Очарованный кварк. Теорема о двух милиционерах. Ну и конечно - матрица! Кто же не знает, что матрица - это когда Киану Ривз бегает по потолку. И не надо нам рассказывать про какие-то таблицы с числами.
Для развития науки вульгарные представления широких масс полезны. Обычных слов следовало бы даже добавить. Фильмов про горизонт событий снять побольше. Натяжек и ляпов не бояться. Главное, чтобы зритель ощущал прикосновение к переднему краю науки и величие человеческого, а, значит, и своего личного разума. Особенно если от такого зрителя зависит принятие решений о финансировании исследований.
Выдающийся советский ядерщик Георгий Флеров говорил: «Объяснять важному начальству научную проблему нужно не так, как правильно, а так, как ему будет понятно. Это ложь во благо». Правильно. Руководство не нужно смущать лекциями про «спонтанные нарушения электрослабой симметрии». Расскажите лучше про «частицу Бога» и «Великую тайну гравитации». Вранья, кстати, в этом особого нет - а инвестиции есть. Не беда, что околонаучные сказки порождают завышенные ожидания и, как следствие, избыточное вливание денег, заканчивающееся разорением. Общая польза в итоге перевешивает. Пузырь доткомов в 2001 году лопнул, но интернет-технологии получили мощнейший импульс.
Нечеткой логике в этом смысле повезло не только с собственным названием, но и с причислением к списку наук и технологий, объединенных названием «искусственный интеллект» - наряду с нейронными сетями, логическим программированием, экспертными системами и др. Это уже большая маркетинговая игра, где участники списка получают эффект от пакетной рекламы в рамках раскрутки единого научного мегабренда. Шутка ли: искусственный интеллект! Вот уж чарующая перспектива понятней некуда. Каждому в дом по железному слуге. Пусть умные кибернетические организмы делают всю работу, а мы будем только вводить пин-коды и пить пина-колады. Ради такого света в конце тоннеля не жаль никаких денег.
Флеровская «ложь во благо» на примере искусственного интеллекта сработала на 100%. Японское правительство с 1982-го по 1992 год потратило полмиллиарда долларов на разработку «компьютера пятого поколения» с элементами «мышления». Как задумывалось, не получилось. В частности, скис язык логического программирования Prolog, которому в 1980-е прочили первые роли. Ну и ладно. Все ж как с доткомами: роботов в некоторых странах в итоге все равно научились делать отличных.
Сегодня кибернетические системы видят, слышат и читают почти как люди, обыгрывают шахматных гроссмейстеров и зачастую эффективнее дипломированных специалистов управляют производственными процессами. Спасибо за столь мощное развитие темы помимо непосредственных разработчиков нужно сказать авторам удачной терминологии, а также Айзеку Азимову, Артуру Кларку, братьям Вачовски и всему коллективу киностудии имени Горького, подарившей советским детям образы роботов-вершителей.
Никаких разумных киборгов при этом на самом деле не создано. Пока даже нельзя уверенно сказать, что, пытаясь их сотворить, мы движемся в правильном направлении. Чтобы убедиться в этом, давайте посмотрим, как в самых общих чертах работает «умная» стиральная машина, которая благодаря блоку управления с нечеткой логикой умеет определять, когда одежда стала уже «достаточно чистой», чтобы слить воду и начать отжим. Пример любопытен еще и тем, что показывает, как практический результат достигается на стыке нескольких дисциплин: физики, химии и математики.
Задача управляющего устройства машины состоит в следующем. Принять на вход данные о степени загрязнения одежды и типе загрязнения. Проанализировать их и сформировать выходной параметр: время стирки.
За оба входных показателя отвечает оптический датчик, который определяет, насколько прозрачен моющий раствор. По степени его прозрачности можно судить о степени загрязнения: чем более грязная одежда загружена в бак, тем менее прозрачен раствор. А тип загрязнения определяется по скорости изменения прозрачности раствора. Жирные вещества плохо растворяются, поэтому чем медленнее изменяется концентрация раствора, тем с более жирным загрязнением приходится иметь дело. Все, датчик работу закончил.
Отметим, что он выдал два точных параметра, два конкретных числа: степень прозрачности раствора и скорость изменения прозрачности раствора. А вот дальше начинает работать алгоритм Ибрагима Мамдани.
На первом этапе, который называется фаззификацией (введением нечеткости), оба числа превращаются в нечеткие понятия. Допустим, мы ввели три градации загрязнения: «слабое», «среднее» и «сильное». Тогда вместо уровня прозрачности раствора появляются три нечетких суждения о загрязнении, скажем: «0,3; слабое», «0,6; среднее», «0,1; сильное».
Что значат эти цифры? Как и в случае с девушкой, чью нечеткую красоту мы обсуждали в начале текста, их можно считать результатами некоего референдума, на котором 30% граждан проголосовали, что загрязнение при данном уровне прозрачности раствора слабое, 60% - что среднее, 10% - сильное. А что, кто-то этот референдум проводил? Можно считать, что да.
В ходе разработки изделия собрались эксперты по машинной стирке и прикинули, как разложатся голоса «избирателей» в зависимости от уровня прозрачности раствора. А не шарлатанство ли это, спросите вы, математика же точная наука, какие еще эксперты по стирке? Да вот такие. Если вы всерьез хотите решить задачу, то найдете стоящих специалистов, чьи прикидки и оценки будут осмысленными и полезными.
Итак, у нас есть один нечеткий параметр «степень загрязнения», теперь нужен второй: «тип загрязнения». Проводим еще один «референдум». Допустим, он показал, что при такой скорости изменения концентрации раствора, которую нам выдал датчик, загрязнение следует считать, например, «0,2; малой жирности», «0,5; средней жирности», «0,3; большой жирности».
Наступает второй этап алгоритма: применение нечетких правил. Теперь вместе с экспертами мы обсуждаем, каким должно быть время стирки в зависимости от степени и типа загрязнения. Перебирая все возможные варианты, получаем - трижды три - девять правил следующего вида: «если загрязнение сильное и средней жирности, то время стирки - большое». Далее по законам логики (мы их для простоты пропустим) подсчитываем степень истинности для времени стирки. Пусть в результате нечеткое время стирки получилось таким: «0,1; малое», «0.7; среднее», «0,2; большое». Можно приступать к заключительному этапу.
Он называется дефаззификацией, то есть ликвидацией нечеткости - нам ведь необходимо дать машине точную вводную, сколько времени вращать барабан. Подходы есть разные, один из распространенных заключается в вычислении «центра тяжести». Допустим, эксперты сказали, что малое время стирки это 20 минут, среднее - 40 минут, большое - 60 минут. Тогда с учетом «веса» каждого значения получаем итоговый параметр: 20*0,1 + 40*0,7 + 60*0,2 = 42. Одежда будет «достаточно чистой» после 42 минут стирки. Ура.
Ибрагим Мамдани придумал красивую штуку, не правда ли? На первый взгляд, чуть ли не шаманство. У вас есть точные исходные цифры и нужно из них получить другие точные цифры. Но вы не корпите над выводом формул, а погружаетесь в мир нечетких понятий, как-то там ими оперируете, а потом возвращаетесь обратно в «точный» мир - с готовым ответом на руках.
Производители стиральных машин даже принялись рекламировать применение нечеткой логики и прямо на изделиях или в инструкциях писать Fuzzy Logic, Fuzzy Control, Logic Control. Бизнесмены люди прагматичные и не размещают каких попало слов на своем товаре. Так что если вы увидели на машине надпись Fuzzy Logic, это значит: она «продает» товар. Технология помимо своих сугубо потребительских свойств гипнотизирует покупателя еще и названием, мотивируя на расставание с лишней сотней долларов. Уж не знаю, получает ли с этого роялти Лотфи Заде, но это было бы справедливо. Ни один другой раздел математики на бытовой технике не упоминается.
Но вы же заметили, наверное, что по ходу описания работы стиральной машины с нечеткой логикой не встретилось ни одного места, где можно было бы заподозрить, что у машины появился собственный разум. Только инструкции вроде служебных, только решение запрограммированных задач. Машина будет вовремя сливать воду. Но она не будет понимать, что она делает и зачем. В ее микропроцессорную голову никогда не придет мысль перестать стирать и ради прикола устроить в ванной потоп. Если только эта мысль не посетит программиста, который для прикола встроит в машину еще какую-нибудь Funny Logic. Сама же машина до такого додуматься не может.
Вот вам и весь искусственный интеллект. Роботы учатся только имитировать человеческую деятельность, пусть даже такую, на которую мы сейчас тратим интеллектуальные усилия, например, на перевод с другого языка. Пусть даже они переводят лучше. Вы же не обижаетесь на подъемный кран, что он сильнее вас. И появление кранов не привело к исчезновению штангистов. Только теперь поднятие тяжестей это спорт и удовольствие, а таскать на себе мешки с цементом на стройке не надо. С переводами то же самое. Программа не умнее нас, просто мы смогли формализовать и эффективно сгрузить на нее некоторые наши умения, и теперь можем не тратить свои интеллектуальные усилия на технические переводы, а заняться, скажем, Шекспиром.
Считать, что машины приобретают интеллект благодаря передовым достижениям кибернетики - все равно что верить в карго-культ. Помните, как жители затерянного острова, увидев в небе самолет, сделали такую же фигуру из соломы и думали, что полетит? Они тогда ничего не знали о металлах и керосине, не говоря уже о подъемной силе - и поди объясни.
Так и у нас с «искусственным интеллектом». Роботы скоро смогут водить автомобили и наверняка когда-нибудь обыграют команду людей в футбол - тем более, что этот момент приближают не только японские инженеры, но и наша сборная. Но это будет не более чем имитация разумных действий на поле. Как те аборигены, мы не знаем пока чего-то критически важного, что позволило бы создать разумное существо.
У нас, говоря словами Станислава Лема, обязательно получится Усилитель Умения Водить Авто - как уже получился Усилитель Умения Остановить Стирку. А вот Усилитель Интеллекта, появление которого предсказывал великий фантаст, на основе нынешних технологий «искусственного интеллекта», в том числе нечеткой логики, несмотря на все ее изящество и полезность, не получится. Нечеткая логика это всего лишь способ сократить объем вычислений при решении некоторого класса задач. И на том спасибо.
Можно не бояться роботов-вершителей. Муки творчества, благородные порывы, научный поиск, мечтательность, достоинство, самопожертвование, готовность к подвигу, авантюризм, честь, дружба, гордость, предубеждение, зависть, алчность, жлобство, чванство, подлость, пошлость, доносительство, разводки, сливы, подставы - во всех этих номинациях мы с вами еще долго будем выступать куда круче наших меньших полупроводниковых собратьев.
Задумывались ли вы когда-нибудь о том, как мыслит человек? Какими словами мы обычно пользуемся, чтобы объяснить меру чего-либо? Выражения «Немного посолить», «слегка остудить», «пройти чуть дальше», «налить много», «принести мало» — совершенно обычны для человека. Именно такими категориями мы воспринимаем окружающую действительность. В нашей обычной жизни мы крайне редко пользуемся чёткими правилами и алгоритмами. У человека нет точных датчиков и измерительных приборов. Вместо этого у нас есть органы чувств и наше врождённое чувство меры. Но это нельзя назвать нашим недостатком, наоборот – в этом заключается наше главное преимущество. Это позволяет нам быть адаптивными. Дело в том, что окружающий мир настолько сложен, что ни одна супер-мега-крутая вычислительная машина не сможет учесть все его зависимости. Поэтому для точных компьютерных вычислений мы обычно упрощаем задачу, идеализируем её, отбрасываем несущественные факторы, принимаем какие-то допущения и т.д. Мы можем это сделать, именно потому, что наше чувство меры позволяет нам оценить «навскидку», какие факторы вносят значительный вклад, а какие несущественны. Однако существует довольно много задач, которые достаточно сложно формализовать, составить для них «чёткий» алгоритм.
Например, сложно представить, что какая-то автоматика будет печь пирожки вкуснее, чем бабушка Зина. Слишком много «нечётких» факторов в этом деле: и дрожжи каждый раз разные, и мука; от влажности и температуры в помещении тоже многое зависит. Только опытная бабушка сможет учесть все эти факторы.
Вот почему во многих случаях полезно наделить управляющее устройство «нечётким мышлением». В системе, где все влияющие на неё факторы учесть сложно или невозможно, — это позволяет заменить человека-эксперта, имеющего большой практический опыт, автоматикой. Сейчас на простом примере разберём, как это делается в технических системах.
На заводе «N» работает крановщик Василий. Трудится он на этом предприятии 40 лет, с того самого момента, как окончил ПТУ. Его задача состоит в том, чтобы поднимать краном паллеты с готовой продукцией и ставить на место складирования. Делать это умеет только Василий. За многие годы практики он чётко научился определять, с какой скоростью нужно двигаться на кране в зависимости от того, какой груз у него на крюке, за сколько метров до цели нужно начать останавливаться, как регулировать угол наклона стрелы крана, чтобы уменьшить раскачивание паллеты на крюке и т.д. Весь этот опыт позволяет ему каждый раз опускать груз точно в цель и делать это на оптимальной скорости.

Однако, Василию скоро на пенсию, а заменить его некому. К тому же, руководство завода взяло курс на автоматизацию производственного процесса. Для того, чтобы заменить крановщика интеллектуальным устройством, необходимо наделить его «нечёткой логикой» и экспертными знаниями Василия. Поехали…
Входы и выходы системы управления
Для начала определим входные и выходные параметры нашей будущей системы управления. Входами будут те критерии, с помощью которых Василий обычно оценивает текущее состояние системы:
- Расстояние до цели
- Амплитуда раскачивания груза на крюке крана
Выходы – управляющие воздействия, которые может вносить в систему крановщик, чтобы менять её текущее состояние:
- Педаль газа — регулирует скорость, влияет на амплитуду раскачивания груза
- Педаль тормоза — влияет на плавность остановки (амплитуду раскачивания груза)
- Ручка управления стрелой крана – регулирует угол наклона стрелы, компенсирует раскачивание груза
Теперь обратимся к самому Василию, чтобы «добыть» из него бесценные экспертные знания.
 Спрашиваем:
Спрашиваем:
— «Василий, скажите, с какой скоростью нужно двигаться, чтобы максимально быстро доставлять груз до цели, но при этом не приходилось резко тормозить перед финишем, заставляя груз сильно раскачиваться?»
Василий ответит примерно следующее:
— «Ну, так это… как только зацепил груз, пока до места еще далеко — давлю газ в пол. В середине пути чуть убавляю и плавненько иду, чтоб не шаталась верёвка. Если сильно шатает – газ жму совсем чуть-чуть и немного наклоняю стрелу в противоход. Когда близко подъезжаю – совсем уже газ отпускаю, наоборот притормаживаю малеху».
Вот мы и получили первые нечёткие правила от Василия. Продолжая общение с ним, узнаем и остальные. Представим все полученные правила, в виде таблицы:

– это перевод входного параметра системы в «нечёткую» область.
Первый входной параметр – «расстояние до цели». В терминах «нечёткой логики» — это лингвистическая переменная , поскольку она принимает в качестве значений не числа, а слова. А в понимании вычислительной машины «расстояние до цели» — вполне чёткий параметр, измеряемый в метрах.
Поэтому на этом этапе нам необходимо выяснить у Василия, что для него «близко», а что «очень близко» — определить его нечёткие диапазоны в цифрах. Например, 15 метров – для него будет однозначно близко. А вот насчёт 6 метров – он будет путаться в показаниях, причисляя это значение то к «близко», то к «очень близко». Поэтому «нечёткие диапазоны» могут перекрывать друг друга. Посмотрим, как это выглядит на графике:

Функцию M(x) называют функцией принадлежности . Она показывает степень принадлежности параметра к одному из нечётких значений. Как видно из графика, расстояние 32 метра со степенью принадлежности 0,2 относится к значению «средне» и со степенью принадлежности 0,65 к значению «близко».
Чем больше степень принадлежности, тем больше вероятность, что вычислительная машина присвоит переменной соответствующее нечёткое значение. Однако не стоит путать функцию принадлежности с функцией вероятностного распределения – это не одно и то же. Поэтому, в частности, сумма степеней принадлежности одного входного параметра к различным нечётким значениям не обязательно равна 1.
Точно такие же функции принадлежности нужно определить и для остальных входных и выходных параметров системы, снова используя экспертные знания крановщика Василия.
Принятие решения
Как только система управления фазифицирует все входные параметры по заданным функциям принадлежности, блок принятия решения найдёт соответствующие значения выходных параметров, пользуясь нечёткими правилами (см. таблицу выше).
Дефазификация
На этом этапе система управления будет делать обратное преобразование из нечётких значений выходных параметров (найденных по таблице) – к чётким цифрам. Математические алгоритмы этих преобразований разнообразны и зависят от конкретной задачи. Подробно на них заморачиваться не имеет смысла — пусть этим занимаются суровые математики. Инженеру нужно лишь реализовать один из известных алгоритмов.
В качестве контроллера нечёткой логики можно использовать уже готовое микропроцессорное устройство, поддерживающее описанные выше алгоритмы. Такому устройству необходимо задать только функции принадлежности всех лингвистических переменных и нечёткие правила. Конечно, если хочется поупражняться – можно взять обычный микроконтроллер и «суровую» книгу по математическим алгоритмам, применяемым в нечёткой логике, и реализовать всё это самому.
В любом случае структура контроллера нечёткой логики будет примерно такой:

Заключение
В этой статье мы рассмотрели базовые понятия нечёткой логики, которая является составной частью более широкого понятия «Искусственный интеллект». Нечёткая логика широко применяется при построении экспертных систем, систем поддержки принятия решений, систем управления, основанных на экспертных знаниях. На очереди статья, в которой мы расскажем, в каких приборах и устройствах, используемых нами в повседневной жизни, применяется нечёткая логика. Да-да, я не оговорился, каждый из нас ежедневно пользуется приборами, обладающими искусственным интеллектом. Но об этом позже, а на сегодня всё! Помните, читая LAZY SMART , вы становитесь ближе к миру новых технологий! До свидания!