Оптимизация MySQL – основы правильной реализации. Оптимизация MySql запросов
От автора: один мой знакомый решил оптимизировать свой автомобиль. Сначала одно колесо снял, потому крышу спилил, затем мотор… В общем, сейчас он пешком ходит. Это все последствия неправильного подхода! Поэтому, чтобы ваша СУБД продолжала «ездить», оптимизация MySQL должна проходить правильно.
Когда оптимизировать и зачем?
Лишний раз лезть в настройки сервера и изменять значения параметров (особенно, если не знаете, чем это может закончиться) не стоит. Если рассматривать данную тему с «колокольни» улучшения производительности веб-ресурсов, то она настолько обширная, что ей нужно посвящать целое научное издание в 7 томах.
Но такого писательского терпения у меня явно нет, да и у вас читательского тоже. Мы поступим проще, и постараемся лишь слегка углубиться в чащи оптимизации MySQL сервера и его составляющих. С помощью оптимальной установки всех параметров СУБД можно достигнуть нескольких целей:
Увеличить скорость выполнения запросов.
Повысить общую производительность сервера.
Уменьшить время ожидания загрузки страниц ресурса.
Снизить потребление серверных мощностей хостинга.
Снизить объем занимаемого дискового пространства.
Постараемся всю тематику оптимизации разбить на несколько пунктов, чтоб было более-менее понятно, от чего «котелок» закипает .
Зачем настраивать сервер
В MySQL оптимизацию производительности следует начинать с сервера. Прежде всего, следует ускорить его работу и уменьшить время обработки запросов. Универсальным средством для достижения всех перечисленных целей является включения кэширования. Не знаете, «what is it»? Сейчас все поясню.
Если на вашем экземпляре сервера включено кэширование, то система MySQL автоматически «запоминает» введенный пользователем запрос. И в следующий раз при его повторении данный результат запроса (на выборку) будет не обработан, а взят из памяти системы. Получается, что таким образом сервер «экономит» время на выдачу ответа, и вследствие чего скорость реагирования сайта повышается. В том числе это касается и общей скорости загрузки.
В MySQL оптимизация запросов применима к тем движкам и CMS, которые работают на основе данной СУБД и PHP. При этом код, написанный на языке программирования, для генерации динамической веб-страницы запрашивает некоторые ее структурные части и содержимое (записи, архивы и другие таксономии) из БД.
Благодаря включенному кэшированию в MySQL выполнение запросов к серверу СУБД происходит намного быстрее. За счет чего и повышается скорость загрузки всего ресурса в целом. А это положительно отражается и на пользовательском опыте, и на позиции сайта в выдаче.
Включаем и настраиваем кэширование
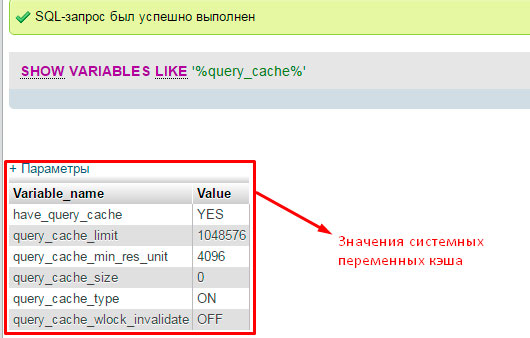
Но давайте вернемся от «скучной» теории к интересной практике. Дальнейшую оптимизацию базы MySQL продолжим с проверки состояния кэширования на вашем сервере БД. Для этого с помощью специального запроса мы выведем значения всех системных переменных:
Совсем другое дело.
Сделаем маленький обзор полученных значений, которые пригодятся нам для оптимизации баз данных MySQL:
have_query_cache – значение показывает «ВКЛ» кэширование запросов или нет.
query_cache_type – отображает активный тип кэша. Нам нужно значение «ON». Это говорит о том, что кэширование включено для всех видов выборки (команда SELECT). Кроме тех, в которых используется параметр SQL_NO_CACHE (запрещает сохранение информации об этом запросе).
У нас все настройки заданы правильно.
Отмеряем кэш под индексы и ключи
Теперь нужно проверить, сколько отведено оперативной памяти под индексы и ключи. Рекомендуется устанавливать этот важный для оптимизации БД MySQL параметр на 20-30% от объема оперативки, доступной для сервера. Например, если под экземпляр СУБД выделено 4 «гектара», то смело ставьте 32 «метра». Но все зависит от особенностей определенной базы и ее структуры (типов) таблиц.
Для установки значения параметра нужно отредактировать содержимое конфигурационного файла my.ini, который в Денвере находится по следующему пути: F:\Webserver\usr\local\mysql-5.5

Файл открываем с помощью Блокнота. Затем находим в нем параметр key_buffer_size и устанавливаем оптимальный для вашей системы ПК (в зависимости от «гектаров» оперативки) размер. После этого нужно перезапустить сервер БД.

В СУБД используется несколько дополнительных подсистем (нижнего уровня), и все основные их настройки также задаются в данном файле конфигурации. Поэтому, если нужно провести в MySQL InnoDB оптимизацию, то добро пожаловать сюда. Более подробно эту тему мы изучим в одном из наших следующих материалов.
Измеряем уровень индексов
Использование индексов в таблицах значительно повышает скорость обработки и формирования ответа СУБД на введенный запрос. MySQL постоянно «измеряет» уровень применения индексов и ключей в каждой БД. Для получения данного значения используйте запрос:
SHOW STATUS LIKE "handler_read%"
SHOW STATUS LIKE "handler_read%" |

В полученном результате нас интересует значение в строке Handler_read_key. Если указанное там число маленькое, то это говорит о том, что индексы почти не используются в данной базе. А это плохо (как у нас ).
→ Оптимизация запросов MySQL
MySQL располагает большим набором функций для различных сортировок (ORDER BY ), группировок (GROUP BY ), объединений (LEFT JOIN или RIGHT JOIN ) и так далее. Все они безусловно удобны, но в условиях одноразовых запросов. К примеру, если лично Вам требуется что-то откопать в базе используя кучу таблиц и связок, то кроме вышеперечисленных функций можно и даже нужно применять условный операторы IF . Главная ошибка начинающих программистов это стремление применить такие запросы в рабочем коде сайта. В данном случае сложный запрос безусловно красив, но вреден. Все дело в том, что любые операторы сортировок, группировок, объединений или вложенных запросов, не могут выполняться в оперативной памяти, и используют жесткий диск для создания временных таблиц. А хард, как известно - самое узкое место сервера.
Правила оптимизации mysql запросов
1. Избегайте вложенных запросов
Это самая серьезная ошибка. Родительский процесс всегда будет ждать завершения дочернего и в это время держать коннект к базе, использовать диск и нагружать iowait. Два параллельных запроса в базу и выполнения нужных фильтраций в серверном интерпретаторе (Perl , PHP и т. д.), выполнятся на порядок быстрее чем вложенный.
Примеры на perl , как делать не следует:
My $sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { my $groupNAME = $dbh->selectrow_array("SELECT groupNAME FROM groups WHERE groupID = $row"); ### Допустим нужно собрать названия групп ### и добавить их в конец массива с данными push @row => $groupNAME; ### Делаем еще что-нибудь... }
или не в коем случае вот так:
My $sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(SELECT groupID FROM groups WHERE groupNAME = "Первая" OR groupNAME = "Вторая" OR groupNAME = "Седьмая")");
Если есть необходимость подобных действий, во всех случаях лучше использовать хеш, массив или любой другой путь для фильтрации.
Пример на perl, как делаю обычно я:
My %groups; my $sth = $dbh->prepare("SELECT groupID,groupNAME FROM groups WHERE groupID IN(2,3,7)"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { $groups{$row} = $row; } ### А теперь выполням основную выборку без вложенного запроса my $sth2 = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)"); $sth2->execute(); while (my @row = $sth2->fetchrow_array()) { push @row => $groups{$row}; ### Делаем еще что-нибудь... }
2. Не сортируйте, не группируйте и не фильтруйте в базе
По возможности не применяйте в своих запросах операторы ORDER BY, GROUP BY, JOIN. Все они используют временные таблицы. Если сортировка или группировка необходима только для вывода элементов, например по алфавиту, лучше выполнить эти действия в переменных интерпретатора.
Примеры на perl, как сортировать не следует:
My $sth = $dbh->prepare("SELECT elementID,elementNAME FROM tbl WHERE groupID IN(2,3,7) ORDER BY elementNAME"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { print qq{$row => $row}; }
Пример на perl, как сортирую обычно я:
My $list = $dbh->selectall_arrayref("SELECT elementID,elementNAME FROM tbl WHERE groupID IN(2,3,7)"); foreach (sort { $a-> cmp $b-> } @$list){ print qq{$_-> => $_->}; }
Так намного быстрее. Особенно заметна разница если данных много. В случае, если нужно отсортировать в perl по нескольким полям, можно применить сортировку Шварца . Если требуется произвольная сортировка ORDER BY RAND() - используйте сортировку random в perl .
3. Используйте индексы
Если от сортировки в базе можно отказаться в некоторых случаях, то от WHERE навряд ли удастся. Поэтому, для полей, по которым будет идти сравнение, необходимо устанавливать индексы. Делаются они просто.
Таким запросом:
ALTER TABLE `any_db`.`any_tbl` ADD INDEX `text_index`(`text_fld`(255));
Где 255 - длина ключа. Для некоторых типов данных он не требуется. Подробности в документации к MySQL.
9 октября 2008 в 23:37Оптимизация MySQL запросов
- MySQL
В повседневной работе приходится сталкиваться с довольно однотипными ошибками при написании запросов.
В этой статье хотелось бы привести примеры того, как НЕ надо писать запросы.
- Выборка всех полей
SELECT * FROM tableПри написании запросов не используйте выборку всех полей - "*". Перечислите только те поля, которые вам действительно нужны. Это сократит количество выбираемых и пересылаемых данных. Кроме этого, не забывайте про покрывающие индексы. Даже если вам на самом деле необходимы все поля в таблице, лучше их перечислить. Во-первых, это повышает читабельность кода. При использовании звездочки невозможно узнать какие поля есть в таблице без заглядывания в нее. Во-вторых, со временем количество столбцов в вашей таблице может изменяться, и если сегодня это пять INT столбцов, то через месяц могут добавиться TEXT и BLOB поля, которые будут замедлять выборку.
- Запросы в цикле.
Нужно четко представлять себе, что SQL - язык, оперирующий множествами. Порой программистам, привыкшим думать терминами процедурных языков, трудно перестроить мышление на язык множеств. Это можно сделать довольно просто, взяв на вооружение простое правило - «никогда не выполнять запросы в цикле». Примеры того, как это можно сделать:1. Выборки
$news_ids = get_list("SELECT news_id FROM today_news ");
while($news_id = get_next($news_ids))
$news = get_row("SELECT title, body FROM news WHERE news_id = ". $news_id);Правило очень простое - чем меньше запросов, тем лучше (хотя из этого, как и из любого правила, есть исключения). Не забывайте про конструкцию IN(). Приведенный код можно написать одним запросом:
SELECT title, body FROM today_news INNER JOIN news USING(news_id)2. Вставки
$log = parse_log();
while($record = next($log))
query("INSERT INTO logs SET value = ". $log["value"]);Гораздо более эффективно склеить и выполнить один запрос:
INSERT INTO logs (value) VALUES (...), (...)3. Обновления
Иногда бывает нужно обновить несколько строк в одной таблице. Если обновляемое значение одинаковое, то все просто:
UPDATE news SET title="test" WHERE id IN (1, 2, 3).Если изменяемое значение для каждой записи разное, то это можно сделать таким запросом:
UPDATE news SET
title = CASE
WHEN news_id = 1 THEN "aa"
WHEN news_id = 2 THEN "bb" END
WHERE news_id IN (1, 2)Наши тесты показывают, что такой запрос выполняется в 2-3 раза быстрее, чем несколько отдельных запросов.
- Выполнение операций над проиндексированными полями
SELECT user_id FROM users WHERE blogs_count * 2 = $valueВ таком запросе индекс использоваться не будет, даже если столбец blogs_count проиндексирован. Для того, чтобы индекс использовался, над проиндексированным полем в запросе не должно выполняться преобразований. Для подобных запросов выносите функции преобразования в другую часть:
SELECT user_id FROM users WHERE blogs_count = $value / 2;Аналогичный пример:
SELECT user_id FROM users WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(registered) <= 10;Не будет использовать индекс по полю registered, тогда как
SELECT user_id FROM users WHERE registered >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);
будет. - Выборка строк только для подсчета их количества
$result = mysql_query(«SELECT * FROM table», $link);
$num_rows = mysql_num_rows($result);
Если вам нужно выбрать количество строк, удовлетворяющих определенному условию, используйте запрос SELECT COUNT(*) FROM table, а не выбирайте все строки лишь для того, чтобы подсчитать их количество. - Выборка лишних строк
$result = mysql_query(«SELECT * FROM table1», $link);
while($row = mysql_fetch_assoc($result) && $i < 20) {
…
}
Если вам нужны только n строк выборки, используйте LIMIT, вместо того, чтобы отбрасывать лишние строки в приложении. - Использование ORDER BY RAND()
SELECT * FROM table ORDER BY RAND() LIMIT 1;Если в таблице больше, чем 4-5 тысяч строк, то ORDER BY RAND() будет работать очень медленно. Гораздо более эффективно будет выполнить два запроса:
Если в таблице auto_increment"ный первичный ключ и нет пропусков:
$rnd = rand(1, query("SELECT MAX(id) FROM table"));
$row = query("SELECT * FROM table WHERE id = ".$rnd);Либо:
$cnt = query("SELECT COUNT(*) FROM table");
$row = query("SELECT * FROM table LIMIT ".$cnt.", 1");
что, однако, так же может быть медленным при очень большом количестве строк в таблице. - Использование большого количества JOIN"ов
SELECT
v.video_id
a.name,
g.genre
FROM
videos AS v
LEFT JOIN
link_actors_videos AS la ON la.video_id = v.video_id
LEFT JOIN
actors AS a ON a.actor_id = la.actor_id
LEFT JOIN
link_genre_video AS lg ON lg.video_id = v.video_id
LEFT JOIN
genres AS g ON g.genre_id = lg.genre_idНужно помнить, что при связи таблиц один-ко многим количество строк в выборке будет расти при каждом очередном JOIN"е. Для подобных случаев более быстрым бывает разбить подобный запрос на несколько простых.
- Использование LIMIT
SELECT… FROM table LIMIT $start, $per_pageМногие думают, что подобный запрос вернет $per_page записей (обычно 10-20) и поэтому сработает быстро. Он и сработает быстро для нескольких первых страниц. Но если количество записей велико, и нужно выполнить запрос SELECT… FROM table LIMIT 1000000, 1000020, то для выполнения такого запроса MySQL сначала выберет 1000020 записей, отбросит первый миллион и вернет 20. Это может быть совсем не быстро. Тривиальных путей решения проблемы нет. Многие просто ограничивают количество доступных страниц разумным числом. Также можно ускорить подобные запросы использованием покрывающих индексов или сторонних решений (например sphinx).
- Неиспользование ON DUPLICATE KEY UPDATE
$row = query("SELECT * FROM table WHERE id=1");If($row)
query("UPDATE table SET column = column + 1 WHERE id=1")
else
query("INSERT INTO table SET column = 1, id=1");Подобную конструкцию можно заменить одним запросом, при условии наличия первичного или уникального ключа по полю id:
INSERT INTO table SET column = 1, id=1 ON DUPLICATE KEY UPDATE column = column + 1
От того, насколько хорошо оптимизированы запросы к базе данных mySQL, сильно зависит степень нагрузки на сервер, а значит и скорость загрузки сайта. Разгрузить сервер и уменьшить время загрузки вашего сайта поможет оптимизация mySQL запросов.

Зачем оптимизировать запросы к базе данных
Владельцы сайтов, находящихся под управлением самописных систем администрирования просто обязаны хорошо понимать, какие запросы к базе данных выполняются быстро и легко, а какие сильно повышают нагрузку на сервер и значительно замедляют скорость загрузки сайта.
Вникнуть в суть дела не помешает и тем веб-мастерам, которые используют известные системы администрирования и любят подключать всевозможные плагины сторонних разработчиков, а так же кастомизировать темы под себя, к примеру, на самой популярной бесплатной CMS – WordPress.
 Некоторые действия можно выполнить разными способами, например, посчитать количество найденных в таблице записей можно при помощи функции mysql_num_rows (но делать этого не рекомендуется), а можно и при помощи конструкции SELECT COUNT(). Нами лично было проведено исследование, в котором мы создали огромную таблицу данных, содержащую несколько сотен тысяч записей и весящую более одного гигабайта, а затем попробовали посчитать количество строк указанными способами.
Некоторые действия можно выполнить разными способами, например, посчитать количество найденных в таблице записей можно при помощи функции mysql_num_rows (но делать этого не рекомендуется), а можно и при помощи конструкции SELECT COUNT(). Нами лично было проведено исследование, в котором мы создали огромную таблицу данных, содержащую несколько сотен тысяч записей и весящую более одного гигабайта, а затем попробовали посчитать количество строк указанными способами.
Результат был виден невооруженным глазом, ведь в случае использования mysql_num_rows, страница подвисала секунд на 5, после чего выводился результат. Во втором же случае мы получали результат в виде количества записей в таблице практически моментально. Нам даже не пришлось замерять время загрузки скрипта при помощи микротаймера, ведь результат был более чем очевиден.
То же самое касается и других конструкций. Некоторые операции с базой данных можно выполнить двумя, тремя, четырьмя и более способами и каждый из них будет отличаться именно скоростью, в то время как результат во всех случаях будет одинаково верным.
Как оптимизировать запросы к базе данных
Для того, чтобы понять, как именно оптимизировать запросы и какие конструкции работают быстрее, а какие медленней, мы снова проведем небольшой опыт и сделаем это прямо сейчас.
Нам придется обратиться за помощью к интерфейсу популярного и очень удобного phpmyadmin. Для того, чтобы начать, нам нужно выбрать одну из имеющихся баз данных и создать в ней тестовую таблицу. Ее название в нашем случае будет довольно банальным – test.
CREATE TABLE `test` (`ID` INT NOT NULL AUTO_INCREMENT , `TITLE` VARCHAR(100) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL , `ANNOUNCEMENT` TEXT CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL , `TEXT` TEXT CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL , PRIMARY KEY (`ID`)) ENGINE = MYISAM ;
 Теперь, когда тестовая таблица у нас уже есть, нужно наполнить ее абстрактными данными. Как видно из структуры только что созданной нам таблицы, нам потребуются следующие данные для заполнения:
Теперь, когда тестовая таблица у нас уже есть, нужно наполнить ее абстрактными данными. Как видно из структуры только что созданной нам таблицы, нам потребуются следующие данные для заполнения:
- Заголовок
- Анонс
- Полный текст
За абстрактными текстами мы по привычке пойдем на сервис Яндекс.Рефераты , созданный как раз для подобных целей. Нам посчастливилось наткнуться на тему «Торсионный фотон в XXI веке», ее и возьмем.
 Мы указали выбранную случайно тему в качестве заголовка, в качестве анонса взяли один средненький абзац текста, а в роли полного текста статьи у нас с вами будет текст, длиной в 4000 символов с пробелами. Для подсчета количества символов в тексте мы воспользовались нашим собственным сервисом и вам рекомендуем считать именно в нем, т.к. там есть возможность учитывать пробелы или нет.
Мы указали выбранную случайно тему в качестве заголовка, в качестве анонса взяли один средненький абзац текста, а в роли полного текста статьи у нас с вами будет текст, длиной в 4000 символов с пробелами. Для подсчета количества символов в тексте мы воспользовались нашим собственным сервисом и вам рекомендуем считать именно в нем, т.к. там есть возможность учитывать пробелы или нет.
Получившийся запрос мы сюда копировать не будем, т. к. это будет более 4000 символов не уникального текста, взятого у самого Яндекса, что довольно дерзко, да и вам это тоже не нужно. Лучше мы набросаем простейший цикл на PHP, который быстро добавит в базу данных столько записей, сколько мы захотим. Для начала это будет 100000 статей.
Чем меньше запросов к базе данных, тем лучше
Уже на этом этапе мы покажем вам распространенную ошибку, которую сами же сейчас специально и допустим.
For($i=1;$i<100000;$i++) { mysql_query("INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст")"); }
В качестве запроса мы вставили скопированный из phpmyadmin код, который был отображен на экране после единичного добавления первой статьи вручную. Сразу хочется отметить, что таким образом запросы к базе данных строить не стоит. Мы это сделали лишь потому, что нам просто нужно было быстро наполнить таблицу случайными данными, а этот запрос пишется быстрее, чем тот, который более оптимален. В этом цикле у нас получилось 99999 отдельных обращений к базе данных (первое мы осуществили вручную из phpmyadmin), что является очень плохим тоном.
Гораздо более правильным решением будет сделать ту же операцию, использовав всего одно обращение к базе данных, перечислив все строки через запятую.
INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст"), (NULL, "Заголовок", "Анонс", "Полный текст"), (NULL, "Заголовок", "Анонс", "Полный текст"), …
Если вернуться к нашему первому способу, то он бы выглядел вот так:
INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст") INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст") INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст") …
Чувствуете разницу? Вариант, в котором используется только одно обращение к базе данных и является оптимальным. Скорость работы этих двух способов, приводящих к одному и тому же результату отличается в разы и видна без всяких измерений невооруженным глазом, поверьте, это действительно так.
Производить выборку только необходимых скрипту полей
Здесь все очень просто – та или иная функция нуждается в определенных данных из целевой таблицы. Очень часто оказывается так, что нужно вытащить вообще все поля, особенно, если таблица довольно большая и этих полей больше 10.
SELECT * FROM `test`
В данном запросе звездочка означает то, что будут извлечены данные из всех полей таблицы test. А что, если этих полей в таблице 20-30 штук или больше? Скрипту скорее всего необходимы лишь некоторые из них, а все остальные, которые не будут никак использоваться, будут выбраны зря. Такая операция будет выполняться медленнее, чем если бы вы указали через запятую только те поля, которые вам действительно нужны в данный момент.
SELECT `ID`, `TITLE` FROM `test`
В этом примере мы вообще не будем касаться анонса и полного текста статьи, что заметно ускорит работу скрипта. Таким образом мы с вами делаем вывод, что под оптимизацией запросов к базе данных понимается так же конкретное указание необходимых полей в запросах и отказ от универсальности в виде звездочки.
Объединение нескольких запросов в один
Мы уже с вами обсудили, что хорошая оптимизация работы с mySQL подразумевает использование минимально возможного количества запросов и привели пример с добавлением данных в таблицу.
 Помимо добавления, данный прием можно и нужно использовать и при выборке данных. А теперь давайте приведем самый простой пример. Представьте себе, что у в вашей базе данных есть две таблицы – первая таблица хранит в себе информацию о зарегистрированных пользователях, а вторая содержит статьи, написанные этими пользователями.
Помимо добавления, данный прием можно и нужно использовать и при выборке данных. А теперь давайте приведем самый простой пример. Представьте себе, что у в вашей базе данных есть две таблицы – первая таблица хранит в себе информацию о зарегистрированных пользователях, а вторая содержит статьи, написанные этими пользователями.
Допустим, вам нужно вывести на экран какую-нибудь случайную статью, а снизу подписать ее именем автора. Связь таблиц между собой в данном случае очевидна и происходит по идентификатору пользователя, т. е. ID пользователя в таблице users должен соответствовать полю USER_ID в таблице posts. Данная связь является стандартной и должна быть понятна всем, без исключения.
Итак, чтобы выбрать случайную статью, вы пишете запрос следующего вида:
$rs_post = mysql_query("SELECT `ID`, `USER_ID`, `TITLE`, `TEXT` FROM `posts` ORDER by RAND() LIMIT 1");
Из таблицы posts случайным образом выберется одна статья. После чего наши действия будут иметь примерно такой вид:
$row_post = mysql_fetch_assoc($rs_post); $userID = $row_post["USER_ID"];
Теперь переменная $userID содержит идентификатор пользователя, являющегося автором этой статьи и для того, чтобы получить его данные, например NAME (имя) и SURNAME (фамилию), вы будете обращаться к таблице users и запрос будет выглядеть примерно так:
$rs_user = mysql_query("SELECT `NAME`, `SURNAME` FROM `users` WHERE `ID` = "".$row_post["USER_ID"]."" LIMIT 1");
Кстати, не забывайте обрамлять одинарными кавычками переменные в запросах, особенно это нужно делать, когда данные поступают извне, при помощи GET или POST. Это создаст дополнительное препятствие для злоумышленников и является одной из мер, направленных на защиту от SQL-инъекций . Итак, вернемся к нашему примеру. После того, как запрос к базе данных был сделан, далее все просто – получаем имя и фамилию и выводим в качестве подписи к статье. Задача выполнена.
Но эти два запроса можно оптимизировать, превратив в один. Для этого мы воспользуемся конструкцией LEFT JOIN:
SELECT `posts`.`ID`, `posts`.`USER_ID`, `posts`.`TITLE`, `posts`.`TEXT`, `users`.`NAME`, `users`.`SURNAME` FROM `posts` LEFT JOIN `users` ON `posts`.`USER_ID` = `users`.`ID` ORDER by RAND() LIMIT 1
Как видите, ничего сложного в приведенной конструкции нет и все интуитивно понятно. Единственное, на что хочется обратить ваше внимание – это явное указание таблиц в паре с полями, т. к. идет выборка сразу из нескольких таблиц. Если же названия каких-то полей совпадают, то следует использовать так называемые mySQL алиасы , чтобы потом не путаться при выводе результата.
Заключение
 Как видите, оптимизировать запросы к базе данных можно и нужно. Если вы думаете, что раз у вас все и так быстро работает, то нет смысла что-либо менять, подождите, когда база данных вашего сайта вырастет в несколько раз, а вместе с этим вырастет и посещаемость. Большая посещаемость подразумевает более частые одновременные обращения к базе данных, размер которой также влияет на скорость выполнения операций.
Как видите, оптимизировать запросы к базе данных можно и нужно. Если вы думаете, что раз у вас все и так быстро работает, то нет смысла что-либо менять, подождите, когда база данных вашего сайта вырастет в несколько раз, а вместе с этим вырастет и посещаемость. Большая посещаемость подразумевает более частые одновременные обращения к базе данных, размер которой также влияет на скорость выполнения операций.
Плохая оптимизация запросов может обнаружиться чуть позже, когда сайт достаточно разрастется, а со временем изменения вносить станет все тяжелей, ведь размеры файлов и количество функций только прибавляется. На сайт добавляют новые фичи, направленные на удобство пользователей. Иными словами, если дело дойдет до определенной точки кипения, можно уже и концов не сыскать и чтобы оптимизировать все обращения к базе данных, раскиданные по сотням файлов, потребуется несколько дней, а может и недель. Поэтому лучше сразу стараться делать хорошо, чтобы не создавать себе лишних проблем в будущем.
Работа с базой данных зачастую самое слабое место в производительности многих web приложений. И об этом должны заботиться не только администраторы баз данных. Программисты должны выбирать правильную структуру таблиц, писать оптимизированные запросы и хороший код. Далее перечислены методы оптимизации работы с MySQL для программистов.
1. Оптимизируйте запросы для кэша запросов
У большинства MySQL серверов включено кэширование запросов. Один из наилучших способов улучшения производительности — просто предоставить кэширование самой базе данных. Когда какой-либо запрос повторяется много раз, его результат берется из кэша, что гораздо быстрее прямого обращения к базе данных. Основная проблема в том, что многие просто используют запросы, которые не могут быть закэшированны:
// запрос не будет кэширован $r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()" ); // а так будет! $today = date("Y-m-d" ); $r = mysql_query("SELECT username FROM user WHERE signup_date >= "$today"" );Причина в том, что в первом запросе используется функция CURDATE(). Это относиться ко всем функциям, подобным NOW(), RAND() и другим, результат которых недетерминирован. Если результат функции может измениться, то MySQL не кэширует такой запрос. В данном примере это можно предотвратить вычислением даты до выполнения запроса.
2. Используйте EXPLAIN для ваших запросов SELECT
// создаем a prepared statement if ($stmt = $mysqli ->prepare("SELECT username FROM user WHERE state=?" )) { // привязываем значения $stmt ->bind_param("s" , $state ); // выполняем $stmt ->execute(); // привязываем результат $stmt ->bind_result($username ); // получаем данные $stmt ->fetch(); printf("%s is from %s\n" , $username , $state ); $stmt ->close(); }13. Небуферизованные запросы
Обычно, делая запрос, скрипт останавливается и ждет результата его выполнения. Вы можете изменить это, используя небуферизованные запросы.
Хорошее описание есть в документации функции mysql_unbuffered_query() :
«mysql_unbuffered_query() отправляет SQL-запрос в MySQL, не извлекая и не автоматически буферизуя результирующие ряды, как это делает mysql_query() . С одной стороны, это сохраняет значительное количество памяти для SQL-запросов, дающих большие результирующие наборы. С другой стороны, вы можете начать работу с результирующим набором срезу после получения первого ряда: вам не нужно ожидать выполнения полного SQL-запроса»
Однако есть определенные ограничения. Вам придется считывать все записи или вызывать mysql_free_result() прежде, чем вы сможете выполнить другой запрос. Так же вы не можете использовать mysql_num_rows() или mysql_data_seek() для результата функции.
14. Храните IP в UNSIGNED INT
Многие программисты хранят IP адреса в поле типа VARCHAR(15), не зная что можно хранить его в целочисленном виде. INT занимает 4 байта и имеет фиксированный размер поля.
Убедитесь, что используете UNSIGNED INT, т.к. IP можно записать как 32 битное беззнаковое число.
Используйте в запросе INET_ATON() для конвертирования IP адреса в число, и INET_NTOA() для обратного преобразования. Такие же, такие функции есть и в PHP — ip2long() и long2ip() (в php эти функции могут вернуть и отрицательные значения. замечание от хабраюзера The_Lion).
15. Таблицы фиксированного размера (статичные) — быстрее
Если каждая колонка в таблице имеет фиксированный размер, то такая таблица называется «статичной» или «фиксированного размера». Пример колонок не фиксированной длины: VARCHAR, TEXT, BLOB. Если включить в таблицу такое поле, она перестанет быть фиксированной и будет обрабатываться MySQL по-другому.
Использование таких таблицы увеличит эффективность, т.к. MySQL может просматривать записи в них быстрее. Когда надо выбрать нужную строку таблицы, MySQL может очень быстро вычислить ее позицию. Если размер записи не фиксирован, ее поиск происходит по индексу.
Так же эти таблицы проще кэшировать и восстанавливать после падения базы. Например, если перевести VARCHAR(20) в CHAR(20), запись будет занимать 20 байтов, вне зависимости от ее реального содержания.
Используя метод «вертикального разделения», вы можете вынести столбцы с переменной длиной строки в отдельную таблицу.
16. Вертикальное разделение
Вертикальное разделение — означает разделение таблицы по столбцам для увеличения производительности.
Пример 1. Если в таблице пользователей хранятся адреса, то не факт что они будут нужны вам очень часто. Вы можете разбить таблицу и хранить адреса в отдельной таблице. Таким образом, таблица пользователей сократиться в размере. Производительность возрастет.
Пример 2. У вас есть поле «last_login» в таблице. Оно обновляется при каждом входе пользователя на сайт. Но все изменения в таблице очищают ее кэш. Храня это поле в другой таблице, вы сведете изменения в таблице пользователей к минимуму.
Но если вы будете постоянно использовать объединение этих таблиц, это приведет к ухудшению производительности.
17. Разделяйте большие запросы DELETE и INSERT
Если вам необходимо сделать большой запрос на удаление или вставку данных, надо быть осторожным, чтобы не нарушить работу приложения. Выполнение большого запроса может заблокировать таблицу и привести к неправильной работе всего приложения.
Apache может выполнять несколько параллельных процессов одновременно. Поэтому он работает более эффективно, если скрипты выполняются как можно быстрее.
Если вы блокируете таблицы на долгий срок (например, на 30 секунд или дольше), то при большой посещаемости сайта, может возникнуть большая очередь процессов и запросов, что может привести к медленной работе сайта или даже к падению сервера.
Если у вас есть такие запросы, используйте LIMIT, чтобы выполнять их небольшими сериями.
18. Маленькие столбцы быстрее
Для базы данных работа с жестким диском, возможно, является самым слабым местом. Маленькие и компактные записи обычно лучше с точки зрения производительности, т.к. уменьшают работу с диском.
В документации к MySQL есть список требований к хранилищам данных для всех типов данных.
Если ваша таблица будет хранить мало строк, то не имеет смысла делать основной ключ типом INT, возможно лучше будет сделать его MEDIUMINT, SMALLINT или даже TINYINT. Если вам не нужно хранить время, используйте DATE вместо DATETIME.
Однако будьте осторожны, что бы не вышло как с Slashdot .
19. Выбирайте правильный тип таблицы
20. Используте ORM
21. Будьте осторожны с постоянными соединениями
Постоянные соединения предназначены для уменьшения расходов на установление связи с MySQL. Когда соединение создается, оно остается открытым после завершения работы скрипта. В следующий раз, этот скрипт воспользуется этим же соединением.
mysql_pconnect() в PHP
Но это звучит хорошо только в теории. Из моего личного опыта (и опыта других), использование этой возможности не оправдывается. У вас будут серьезные проблемы с ограничением по числу подключений, памятью и так далее.
Apache создает много параллельных потоков. Это основная причина, почему постоянные соединения не работаю так хорошо, как бы хотелось. Перед использованием mysql_pconnect() посоветуйтесь с вашим сисадмином.