
Нейросети для начинающих – нейронная сеть для чайников. Простыми словами о сложном: что такое нейронные сети
От vc.ru том, как за несколько шагов создать простую нейронную сеть и научить её узнавать известных предпринимателей на фотографиях.
Шаг 0. Разбираемся, как устроены нейронные сети
Проще всего разобраться с принципами работы нейронных сетей можно на примере Teachable Machine — образовательного проекта Google.
В качестве входящих данных — то, что нужно обработать нейронной сети — в Teachable Machine используется изображение с камеры ноутбука. В качестве выходных данных — то, что должна сделать нейросеть после обработки входящих данных — можно использовать гифку или звук.
Например, можно научить Teachable Machine при поднятой вверх ладони говорить «Hi». При поднятом вверх большом пальце — «Cool», а при удивленном лице с открытым ртом — «Wow».
Для начала нужно обучить нейросеть. Для этого поднимаем ладонь и нажимаем на кнопку «Train Green» — сервис делает несколько десятков снимков, чтобы найти на изображениях закономерность. Набор таких снимков принято называть «датасетом».
Теперь остается выбрать действие, которое нужно вызывать при распознании образа — произнести фразу, показать GIF или проиграть звук. Аналогично обучаем нейронную сеть распознавать удивленное лицо и большой палец.
Как только нейросеть обучена, её можно использовать. Teachable Machine показывает коэффициент «уверенности» — насколько система «уверена», что ей показывают один из навыков.
Шаг 1. Готовим компьютер к работе с нейронной сетью
Теперь сделаем свою нейронную сеть, которая при отправке изображения будет сообщать о том, что изображено на картинке. Сначала научим нейронную сеть распознавать цветы на картинке: ромашку, подсолнух, одуванчик, тюльпан или розу.
Для создания собственной нейронной сети понадобится Python — один из наиболее минималистичных и распространенных языков программирования, и TensorFlow — открытая библиотека Google для создания и тренировки нейронных сетей.
Устанавливаем Python
Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число - ответ. Теперь о самих нейронных сетях.Что такое нейронная сеть?

Нейронная сеть - это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей - это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:Классификация - распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание - возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание - в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?

Нейрон - это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ - это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр - вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример - смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов - это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?

В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H - скрытый нейрон, а буквой w - веса. Из формулы видно, что входная информация - это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации - это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия - это диапазон значений.Линейная функция

Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид

Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет - это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.
Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка - это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.С нейронными сетями я познакомился довольно давно. Отношение к ним, как к средству решения прикладных задач, у меня довольно противоречивое. С одной стороны, ни одной задачи, для которых я использовал сети, решить с удовлетворяющим меня результатом я так и не смог (но нужно оговориться, что и задачи были сверхсложные), а с другой стороны, удалось в достаточной степени оценить мощь аналитического потенциала нейронных сетей и их способность давать оценки и прогнозы на самых разнообразных множествах.
Так как интерес мой к сетям периодически возникал на протяжении последних лет, то идея написать обработку для построения и обучения нейронной сети витала, что называется, в воздухе. Однако, реализовать идею удалось только в последние несколько (честно, даже не помню сколько) месяцев. Борьба за себя - это прежде всего борьба с собой, а точнее, с собственной ленью и невежеством. И этот раунд остался за мной:) Так как делал прежде всего для себя - выкладываю то, что получилось, совершенно даром.
Что из себя представляет данная разработка? Перечислю основные возможности и функционал. При этом имеем в виду и помним, что реализована она только на управляемых формах.
1. Панель управления проектом . В принятых мной терминах под заданием понимается совокупность собственно нейронной сети, исходных данных для обучения, настроек параметров обучения и сохранения результатов. Панель управления проектом позволяет редактировать компоненты задания (кроме нейронной сети), управлять процессом обучения и контролировать результаты обучения сети. Также присутствуют возможности сохранения и загрузки заданий и готовых сетей. Отдельно отмечу наличие опции сохранения результатов. Если в проекте имеется загруженная / созданная сеть и загружен массив исходных данных то по параметрам сети происходит расчет и выгрузка результатов во внешний файл (таблицу значений или книгу Excel). Аналогично можно узнать результаты возвращаемые сетью для любого набора интерактивно введенных аргументов.
2. Редактор нейронной сети (многослойного персептона). Дает возможность создавать и редактировать нейронную сеть. Визуально сеть отображается в виде структуры из разноцветных шаров. Зеленые шары - входные ядра, красные - выходные, а желтые - ядра внутренних слоев. Имеется возможность устанавливать количество слоев и ядер в них. Для загруженных заданий и сетей, а также в случае, когда для обучения проекта уже были загружены данные, количество входных и выходных ядер принимается равным количеству существующих аргументов и результатов. При нажатии кнопки "Сохранить сеть" происходит сохранение сети в параметрах обработки и инициализация начальных весов ребер случайным образом. То есть даже если мы не изменяли структуру сети ее можно очистить от результатов предыдущего обучения заново сохранив в редакторе.
3. Подсистема анализа хода обучения . Подсистема очень проста и представляет собой график, демонстрирующий ход обучения сети в данном проекте. Шаг сбора статистики и общее число шагов обучения настраиваются в "Панели управления проектом". Статистику нельзя видеть в real time по ходу обучения. Она является такой же составной частью проекта, как сеть и массивы данных для обучения и будет обновлена и записана в проект по завершению обучения вместе с новыми параметрами сети. Соответственно если в загруженном проекте при предыдущем обучении была включена опция ведения статистики то просмотр графиков ошибок аппроксимации доступен сразу после загрузки задания (проекта).
4. Модуль обработки . Модуль обработки я также выделяю в отдельную подсистему из-за наличия экспортных функций и процедур, позволяющих проводить обучение сетей и получать результаты расчетов из сети, используя внешние вызовы. Собственно для меня эти функции и являются самыми важными в разработке. Файл со спецификацией проекта прилагается и любой проект, созданный любым способом в соответствии с данной спецификацией может быть обучен, и может быть получен нужный результат из созданной в соответствии со спецификацией сети. Но так как на практике создание, редактирование и обучение сетей довольно трудоемкий и творческий процесс, то визуальные редакторы и панель управления - вполне логичный шаг для упрощения и повышения качества работы. Но еще раз повторюсь - в теории можно было бы обойтись без них, так как модуль обработки представляет собой полностью достаточный функционал для работы с готовыми заданиями и сетями. Остальные подсистемы это лишь мой вариант дизайна кухни для их приготовления.
Теперь немного расскажу о параметрах сети и о процессе обучения.
Среди множества активационных функций нейронов для данного проекта я выбрал логистический сигмоид Ферми. Самая популярная функция в нейронных сетях и (если понимаете в чем суть обучения) очень просто дифференцируема.
Алгоритм обучения - обратное распространение ошибки. За подробностями, если интересно, к Google.
Норма скорости обучения - адаптивная. На страте принимается значение, указанное в параметрах, но по ходу обучения скорость обучения может меняться. Принцип модификации скорости состоит в том, что в случае когда между шагами обучения направление градиента для ребра сети не меняется скорость обучения умножается на коэффициент К>1, а в случае изменения знака градиента множитель К становится <1. Таким образом, норма обучения хотя и остается важнейшим параметром обучения, но ее неправильный выбор может быть в значительной степени скорректирован модификаторами.
Обучающая выборка . Все переданные в качестве аргументов и результатов данные рандомно делятся перед началом обучения на 3 части (Тренировочная, Тестовая и Верификационная) в соотношении 7:2:1. Причем этот рандом каждый раз разный и данные делятся перед каждым циклом обучения. В итоге Вы видите картину, что при запуске второго (третьего и т.д.) цикла обучения одного и того же проекта ошибки аппроксимации могут на первых шагах резко просесть или подскочить. Это не от того что была взята не та сеть - просто новый рандом выборок и новые значения ошибок.
Что же это за выборки? Тренировочная - понятно. Тестовая - не участвует прямо в обучении, но ее ошибка видна в процессе. Судя по значению тренировочной ошибки, а точнее видя ее динамику в сравнении с ошибкой тренировки можно судить о том не переучена ли сеть (ошибки расходятся) и вообще насколько адекватно данным построена модель сети.
Верификационная выборка - не видна пользователю до самого конца обучения. Так как в процессе обучения мы можем следить за тестовой выборкой, то она тоже косвенно является объектом обучения. В данном случае верификация - финальный и самый непредвзятый судья качества получившейся сети.
Классический пример переучившейся сети это когда ошибки тренировки и теста сначала снижаются, а потом расходятся и ошибка теста бесконечно возрастает. Сеть, возможно, сумела "запомнить" всю тренировочную выборку и теперь подстраивается не под обобщающие характеристики всей выборки, а "шлифует" только тренировочные данные. Как правило это случается когда исходная выборка слишком мала или слишком однородна и / или количество внутренних слоев и нейронов при этом слишком велико.
Теперь о способах запуска процесса обучения из формы обработки. Их всего 3:
1. Обычный запуск процесса. Стартуем обучение в текущем сеансе и ждем окончания. Так как до окончания вызова сервера ничего на клиент вернуть нельзя - ждем и надеемся, что все будет хорошо.
2. Запуск через фоновое задание из внешней обработки. Думаю, что здесь все более или менее понятно. Естественно, что обработка должна быть зарегистрирована в справочнике дополнительных отчетов и обработок и в конфигурации должна присутствовать БСП версии не ниже 1.2.1.4. В этом случае у меня все прекрасно работает.
3. Запуск через фоновое задание обработки конфигурации. Это если Вам так понравится обработка, что Вы начнете ее регулярно использовать и встроите в конфигурацию. Здесь, конечно, можно было бы рекомендовать Вам сделать запускающий фоновое задание допил, но можно попробовать и через БСП. Вот только версия должна быть даже не знаю уже какая, но довольно свежая.
Варианты с запуском в фоновом задании наиболее удобны и информативны, так как на форме все-таки что-то можно еще делать, да и информация по ходу обучения периодически обновляется за счет получения и обработки сообщений от фонового задания.
Пару слов скажу еще об опции предварительного обучения. Не буду давать ссылку на умную статью, где доказывается, что предварительный подбор весов нейронных синапсов дает существенный прирост в качестве и сокращение времени обучения сети. Скажу лишь что поверил уважаемым кандидатам наук на слово. Написал блок предварительного подбора и оценки начальных весов и... существенного прогресса не заметил. Здесь уж или лыжи не едут или со мной не все так как нужно, но опцию сохранил. Можете пользоваться перед началом обучения новой сети, а можете не пользоваться.
Что в приложенном архиве? Описание состава проекта сети (спецификация) для самостоятельной разработки проектов (MS Word ), демо-файлы проекта и сети, а также набор из 2-х файлов демо данных. Данные - это таблицы значений с наборами аргументов и результатов.
Обработка выложена отдельным файлом для удобства обновления и замены новыми версиями. Самая важная часть дополнительных материалов - спецификация проекта сети содержится в справке обработки, так что в принципе можно скачивать только саму обработку для экономии $ m . Функционал и документацию при этом Вы получите в полном объеме.
На этом, думаю, стоит заканчивать. Текста и так получилось многовато. Естественно, что по ходу использования обработки на конкретных данных и реальных примерах, у Вас будет возникать множество вопросов и замечаний. Основные ответы и советы приведены выше - то есть сначала внимательно читаем описание. Есть также справка в главной форме обработки. Ее тоже можно почитать. Ну а для всего остального, что не описано или не понятно - комменты.
Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, . Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры .
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Что такое нейронная сеть?
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
Нейронные сети состоят из следующих компонентов:
- входной слой, x
- произвольное количество скрытых слоев
- выходной слой, ŷ
- набор весов и смещений между каждым слоем W и b
- выбор для каждого скрытого слоя σ ; в этой работе мы будем использовать функцию активации Sigmoid
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Обучение нейронной сети
Выход ŷ простой двухслойной нейронной сети:
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как .
Каждая итерация обучающего процесса состоит из следующих шагов
- вычисление прогнозируемого выхода ŷ, называемого прямым распространением
- обновление весов и смещений, называемых
Последовательный график ниже иллюстрирует процесс:
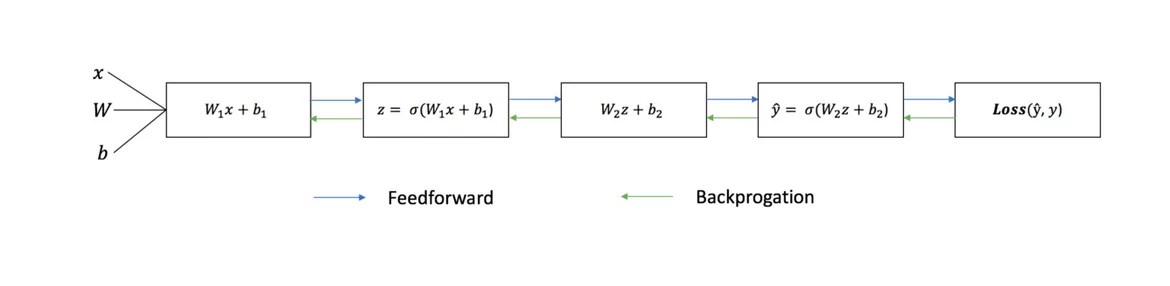
Прямое распространение
Как мы видели на графике выше, прямое распространение - это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Функция потери
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок - это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения - найти набор весов и смещений, который минимизирует функцию потери.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции - это тангенс угла наклона функции.

Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется .
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.
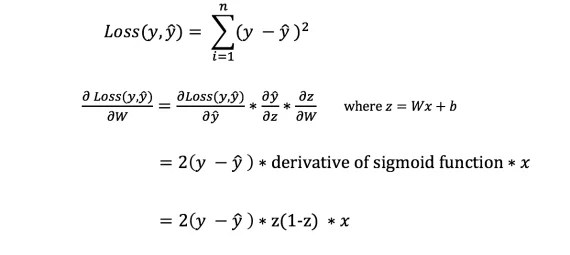
Фух! Это было громоздко, но позволило получить то, что нам нужно - производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Проверка работы нейросети
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весов Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.

Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.

Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Финальные размышления
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!
В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Шаг 1. Нейроны и метод прямого распространения
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод - это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это - ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть - процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
Шаг 2. Сигмоида
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera , посвящённой нейронным сетям - она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды , так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса , поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть .
Вам необязательно делать это самим, поскольку тут требуются специальные знания - главное, чтобы вы поняли, как устроена сигмоида.
Шаг 3. Метод обратного распространения ошибки
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется