
Характеристики искусственной нейронной системы. Для тех, кто хочет знать больше
Добрый день, меня зовут Наталия Ефремова, и я research scientist в компании NtechLab. Сегодня я буду рассказывать про виды нейронных сетей и их применение.
Сначала скажу пару слов о нашей компании. Компания новая, может быть многие из вас еще не знают, чем мы занимаемся. В прошлом году мы выиграли состязание MegaFace . Это международное состязание по распознаванию лиц. В этом же году была открыта наша компания, то есть мы на рынке уже около года, даже чуть больше. Соответственно, мы одна из лидирующих компаний в распознавании лиц и обработке биометрических изображений.
Первая часть моего доклада будет направлена тем, кто незнаком с нейронными сетями. Я занимаюсь непосредственно deep learning. В этой области я работаю более 10 лет. Хотя она появилась чуть меньше, чем десятилетие назад, раньше были некие зачатки нейронных сетей, которые были похожи на систему deep learning.
В последние 10 лет deep learning и компьютерное зрение развивались неимоверными темпами. Все, что сделано значимого в этой области, произошло в последние лет 6.
Я расскажу о практических аспектах: где, когда, что применять в плане deep learning для обработки изображений и видео, для распознавания образов и лиц, поскольку я работаю в компании, которая этим занимается. Немножко расскажу про распознавание эмоций, какие подходы используются в играх и робототехнике. Также я расскажу про нестандартное применение deep learning, то, что только выходит из научных институтов и пока что еще мало применяется на практике, как это может применяться, и почему это сложно применить.
Доклад будет состоять из двух частей. Так как большинство знакомы с нейронными сетями, сначала я быстро расскажу, как работают нейронные сети, что такое биологические нейронные сети, почему нам важно знать, как это работает, что такое искусственные нейронные сети, и какие архитектуры в каких областях применяются.
Сразу извиняюсь, я буду немного перескакивать на английскую терминологию, потому что большую часть того, как называется это на русском языке, я даже не знаю. Возможно вы тоже.
Итак, первая часть доклада будет посвящена сверточным нейронным сетям. Я расскажу, как работают convolutional neural network (CNN), распознавание изображений на примере из распознавания лиц. Немного расскажу про рекуррентные нейронные сети recurrent neural network (RNN) и обучение с подкреплением на примере систем deep learning.
В качестве нестандартного применения нейронных сетей я расскажу о том, как CNN работает в медицине для распознавания воксельных изображений, как используются нейронные сети для распознавания бедности в Африке.
Что такое нейронные сети
Прототипом для создания нейронных сетей послужили, как это ни странно, биологические нейронные сети. Возможно, многие из вас знают, как программировать нейронную сеть, но откуда она взялась, я думаю, некоторые не знают. Две трети всей сенсорной информации, которая к нам попадает, приходит с зрительных органов восприятия. Более одной трети поверхности нашего мозга заняты двумя самыми главными зрительными зонами - дорсальный зрительный путь и вентральный зрительный путь.Дорсальный зрительный путь начинается в первичной зрительной зоне, в нашем темечке и продолжается наверх, в то время как вентральный путь начинается на нашем затылке и заканчивается примерно за ушами. Все важное распознавание образов, которое у нас происходит, все смыслонесущее, то что мы осознаём, проходит именно там же, за ушами.
Почему это важно? Потому что часто нужно для понимания нейронных сетей. Во-первых, все об этом рассказывают, и я уже привыкла что так происходит, а во-вторых, дело в том, что все области, которые используются в нейронных сетях для распознавания образов, пришли к нам именно из вентрального зрительного пути, где каждая маленькая зона отвечает за свою строго определенную функцию.
Изображение попадает к нам из сетчатки глаза, проходит череду зрительных зон и заканчивается в височной зоне.
В далекие 60-е годы прошлого века, когда только начиналось изучение зрительных зон мозга, первые эксперименты проводились на животных, потому что не было fMRI. Исследовали мозг с помощью электродов, вживлённых в различные зрительные зоны.
Первая зрительная зона была исследована Дэвидом Хьюбелем и Торстеном Визелем в 1962 году. Они проводили эксперименты на кошках. Кошкам показывались различные движущиеся объекты. На что реагировали клетки мозга, то и было тем стимулом, которое распознавало животное. Даже сейчас многие эксперименты проводятся этими драконовскими способами. Но тем не менее это самый эффективный способ узнать, что делает каждая мельчайшая клеточка в нашем мозгу.
Таким же способом были открыты еще многие важные свойства зрительных зон, которые мы используем в deep learning сейчас. Одно из важнейших свойств - это увеличение рецептивных полей наших клеток по мере продвижения от первичных зрительных зон к височным долям, то есть более поздним зрительным зонам. Рецептивное поле - это та часть изображения, которую обрабатывает каждая клеточка нашего мозга. У каждой клетки своё рецептивное поле. Это же свойство сохраняется и в нейронных сетях, как вы, наверное, все знаете.
Также с возрастанием рецептивных полей увеличиваются сложные стимулы, которые обычно распознают нейронные сети.
Здесь вы видите примеры сложности стимулов, различных двухмерных форм, которые распознаются в зонах V2, V4 и различных частях височных полей у макак. Также проводятся некоторое количество экспериментов на МРТ.

Здесь вы видите, как проводятся такие эксперименты. Это 1 нанометровая часть зон IT cortex"a мартышки при распознавании различных объектов. Подсвечено то, где распознается.
Просуммируем. Важное свойство, которое мы хотим перенять у зрительных зон - это то, что возрастают размеры рецептивных полей, и увеличивается сложность объектов, которые мы распознаем.
Компьютерное зрение
До того, как мы научились это применять к компьютерному зрению - в общем, как такового его не было. Во всяком случае, оно работало не так хорошо, как работает сейчас.Все эти свойства мы переносим в нейронную сеть, и вот оно заработало, если не включать небольшое отступление к датасетам, о котором расскажу попозже.
Но сначала немного о простейшем перцептроне. Он также образован по образу и подобию нашего мозга. Простейший элемент напоминающий клетку мозга - нейрон. Имеет входные элементы, которые по умолчанию располагаются слева направо, изредка снизу вверх. Слева это входные части нейрона, справа выходные части нейрона.
Простейший перцептрон способен выполнять только самые простые операции. Для того, чтобы выполнять более сложные вычисления, нам нужна структура с большим количеством скрытых слоёв.

В случае компьютерного зрения нам нужно еще больше скрытых слоёв. И только тогда система будет осмысленно распознавать то, что она видит.
Итак, что происходит при распознавании изображения, я расскажу на примере лиц.
Для нас посмотреть на эту картинку и сказать, что на ней изображено именно лицо статуи, достаточно просто. Однако до 2010 года для компьютерного зрения это было невероятно сложной задачей. Те, кто занимался этим вопросом до этого времени, наверное, знают насколько тяжело было описать объект, который мы хотим найти на картинке без слов.
Нам нужно это было сделать каким-то геометрическим способом, описать объект, описать взаимосвязи объекта, как могут эти части относиться к друг другу, потом найти это изображение на объекте, сравнить их и получить, что мы распознали плохо. Обычно это было чуть лучше, чем подбрасывание монетки. Чуть лучше, чем chance level.
Сейчас это происходит не так. Мы разбиваем наше изображение либо на пиксели, либо на некие патчи: 2х2, 3х3, 5х5, 11х11 пикселей - как удобно создателям системы, в которой они служат входным слоем в нейронную сеть.
Сигналы с этих входных слоёв передаются от слоя к слою с помощью синапсов, каждый из слоёв имеет свои определенные коэффициенты. Итак, мы передаём от слоя к слою, от слоя к слою, пока мы не получим, что мы распознали лицо.
Условно все эти части можно разделить на три класса, мы их обозначим X, W и Y, где Х - это наше входное изображение, Y - это набор лейблов, и нам нужно получить наши веса. Как мы вычислим W?
При наличии нашего Х и Y это, кажется, просто. Однако то, что обозначено звездочкой, очень сложная нелинейная операция, которая, к сожалению, не имеет обратной. Даже имея 2 заданных компоненты уравнения, очень сложно ее вычислить. Поэтому нам нужно постепенно, методом проб и ошибок, подбором веса W сделать так, чтобы ошибка максимально уменьшилась, желательно, чтобы стала равной нулю.

Этот процесс происходит итеративно, мы постоянно уменьшаем, пока не находим то значение веса W, которое нас достаточно устроит.
К слову, ни одна нейронная сеть, с которой я работала, не достигала ошибки, равной нулю, но работала при этом достаточно хорошо.

Перед вами первая сеть, которая победила на международном соревновании ImageNet в 2012 году. Это так называемый AlexNet. Это сеть, которая впервые заявила о себе, о том, что существует convolutional neural networks и с тех самых пор на всех международных состязаниях уже convolutional neural nets не сдавали своих позиций никогда.
Несмотря на то, что эта сеть достаточно мелкая (в ней всего 7 скрытых слоёв), она содержит 650 тысяч нейронов с 60 миллионами параметров. Для того, чтобы итеративно научиться находить нужные веса, нам нужно очень много примеров.
Нейронная сеть учится на примере картинки и лейбла. Как нас в детстве учат «это кошка, а это собака», так же нейронные сети обучаются на большом количестве картинок. Но дело в том, что до 2010 не существовало достаточно большого data set’a, который способен был бы научить такое количество параметров распознавать изображения.
Самые большие базы данных, которые существовали до этого времени: PASCAL VOC, в который было всего 20 категорий объектов, и Caltech 101, который был разработан в California Institute of Technology. В последнем была 101 категория, и это было много. Тем же, кто не сумел найти свои объекты ни в одной из этих баз данных, приходилось стоить свои базы данных, что, я скажу, страшно мучительно.
Однако, в 2010 году появилась база ImageNet, в которой было 15 миллионов изображений, разделённые на 22 тысячи категорий. Это решило нашу проблему обучения нейронных сетей. Сейчас все желающие, у кого есть какой-либо академический адрес, могут спокойно зайти на сайт базы, запросить доступ и получить эту базу для тренировки своих нейронных сетей. Они отвечают достаточно быстро, по-моему, на следующий день.
По сравнению с предыдущими data set’ами, это очень большая база данных.

На примере видно, насколько было незначительно все то, что было до неё. Одновременно с базой ImageNet появилось соревнование ImageNet, международный challenge, в котором все команды, желающие посоревноваться, могут принять участие.
В этом году победила сеть, созданная в Китае, в ней было 269 слоёв. Не знаю, сколько параметров, подозреваю, тоже много.
Архитектура глубинной нейронной сети
Условно ее можно разделить на 2 части: те, которые учатся, и те, которые не учатся.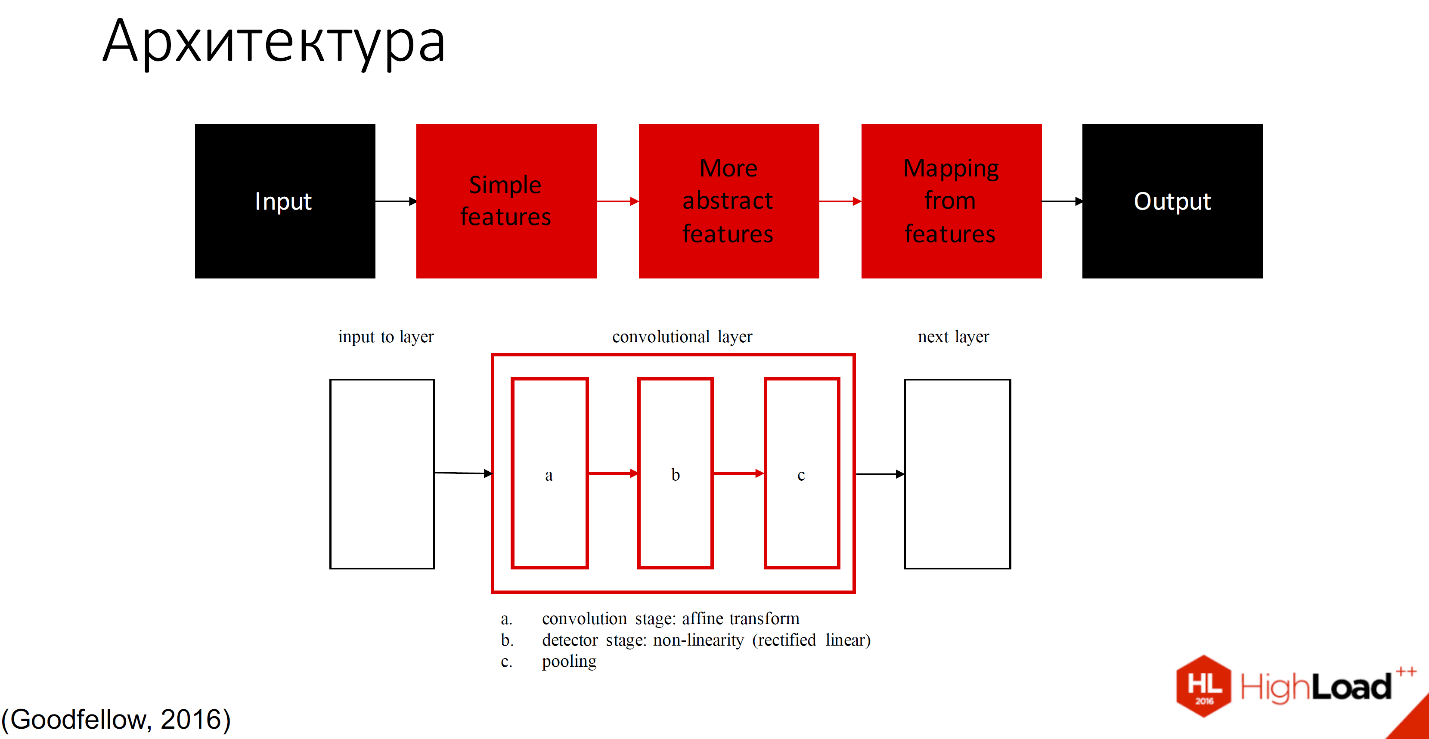
Чёрным обозначены те части, которые не учатся, все остальные слои способны обучаться. Существует множество определений того, что находится внутри каждого сверточного слоя. Одно из принятых обозначений - один слой с тремя компонентами разделяют на convolution stage, detector stage и pooling stage.
Не буду вдаваться в детали, еще будет много докладов, в которых подробно рассмотрено, как это работает. Расскажу на примере.
Поскольку организаторы просили меня не упоминать много формул, я их выкинула совсем.

Итак, входное изображение попадает в сеть слоёв, которые можно назвать фильтрами разного размера и разной сложности элементов, которые они распознают. Эти фильтры составляют некий свой индекс или набор признаков, который потом попадает в классификатор. Обычно это либо SVM, либо MLP - многослойный перцептрон, кому что удобно.
По образу и подобию с биологической нейронной сетью объекты распознаются разной сложности. По мере увеличения количества слоёв это все потеряло связь с cortex’ом, поскольку там ограничено количество зон в нейронной сети. 269 или много-много зон абстракции, поэтому сохраняется только увеличение сложности, количества элементов и рецептивных полей.

Если рассмотреть на примере распознавания лиц, то у нас рецептивное поле первого слоя будет маленьким, потом чуть побольше, побольше, и так до тех пор, пока наконец мы не сможем распознавать уже лицо целиком.

С точки зрения того, что находится у нас внутри фильтров, сначала будут наклонные палочки плюс немного цвета, затем части лиц, а потом уже целиком лица будут распознаваться каждой клеточкой слоя.
Есть люди, которые утверждают, что человек всегда распознаёт лучше, чем сеть. Так ли это?
В 2014 году ученые решили проверить, насколько мы хорошо распознаем в сравнении с нейронными сетями. Они взяли 2 самые лучшие на данный момент сети - это AlexNet и сеть Мэттью Зиллера и Фергюса, и сравнили с откликом разных зон мозга макаки, которая тоже была научена распознавать какие-то объекты. Объекты были из животного мира, чтобы обезьяна не запуталась, и были проведены эксперименты, кто же распознаёт лучше.
Так как получить отклик от мартышки внятно невозможно, ей вживили электроды и мерили непосредственно отклик каждого нейрона.
Оказалось, что в нормальных условиях клетки мозга реагировали так же хорошо, как и state of the art model на тот момент, то есть сеть Мэттью Зиллера.
Однако при увеличении скорости показа объектов, увеличении количества шумов и объектов на изображении скорость распознавания и его качество нашего мозга и мозга приматов сильно падают. Даже самая простая сверточная нейронная сеть распознаёт объекты лучше. То есть официально нейронные сети работают лучше, чем наш мозг.
Классические задачи сверточных нейронных сетей
Их на самом деле не так много, они относятся к трём классам. Среди них - такие задачи, как идентификация объекта, семантическая сегментация, распознавание лиц, распознавание частей тела человека, семантическое определение границ, выделение объектов внимания на изображении и выделение нормалей к поверхности. Их условно можно разделить на 3 уровня: от самых низкоуровневых задач до самых высокоуровневых задач.
На примере этого изображения рассмотрим, что делает каждая из задач.
- Определение границ - это самая низкоуровневая задача, для которой уже классически применяются сверточные нейронные сети.
- Определение вектора к нормали позволяет нам реконструировать трёхмерное изображение из двухмерного.
- Saliency, определение объектов внимания - это то, на что обратил бы внимание человек при рассмотрении этой картинки.
- Семантическая сегментация позволяет разделить объекты на классы по их структуре, ничего не зная об этих объектах, то есть еще до их распознавания.
- Семантическое выделение границ - это выделение границ, разбитых на классы.
- Выделение частей тела человека .
- И самая высокоуровневая задача - распознавание самих объектов , которое мы сейчас рассмотрим на примере распознавания лиц.
Распознавание лиц
Первое, что мы делаем - пробегаем face detector"ом по изображению для того, чтобы найти лицо. Далее мы нормализуем, центрируем лицо и запускаем его на обработку в нейронную сеть. После чего получаем набор или вектор признаков однозначно описывающий фичи этого лица.
Затем мы можем этот вектор признаков сравнить со всеми векторами признаков, которые хранятся у нас в базе данных, и получить отсылку на конкретного человека, на его имя, на его профиль - всё, что у нас может храниться в базе данных.
Именно таким образом работает наш продукт FindFace - это бесплатный сервис, который помогает искать профили людей в базе «ВКонтакте».
Кроме того, у нас есть API для компаний, которые хотят попробовать наши продукты. Мы предоставляем сервис по детектированию лиц, по верификации и по идентификации пользователей.
Сейчас у нас разработаны 2 сценария. Первый - это идентификация, поиск лица по базе данных. Второе - это верификация, это сравнение двух изображений с некой вероятностью, что это один и тот же человек. Кроме того, у нас сейчас в разработке распознавание эмоций, распознавание изображений на видео и liveness detection - это понимание, живой ли человек перед камерой или фотография.
Немного статистики. При идентификации, при поиске по 10 тысячам фото у нас точность около 95% в зависимости от качества базы, 99% точность верификации. И помимо этого данный алгоритм очень устойчив к изменениям - нам необязательно смотреть в камеру, у нас могут быть некие загораживающие предметы: очки, солнечные очки, борода, медицинская маска. В некоторых случаях мы можем победить даже такие невероятные сложности для компьютерного зрения, как и очки, и маска.
Очень быстрый поиск, затрачивается 0,5 секунд на обработку 1 миллиарда фотографий. Нами разработан уникальный индекс быстрого поиска. Также мы можем работать с изображениями низкого качества, полученных с CCTV-камер. Мы можем обрабатывать это все в режиме реального времени. Можно загружать фото через веб-интерфейс, через Android, iOS и производить поиск по 100 миллионам пользователей и их 250 миллионам фотографий.
Как я уже говорила мы заняли первое место на MegaFace competition - аналог для ImageNet, но для распознавания лиц. Он проводится уже несколько лет, в прошлом году мы были лучшими среди 100 команд со всего мира, включая Google.
Рекуррентные нейронные сети
Recurrent neural networks мы используем тогда, когда нам недостаточно распознавать только изображение. В тех случаях, когда нам важно соблюдать последовательность, нам нужен порядок того, что у нас происходит, мы используем обычные рекуррентные нейронные сети.Это применяется для распознавания естественного языка, для обработки видео, даже используется для распознавания изображений.
Про распознавание естественного языка я рассказывать не буду - после моего доклада еще будут два, которые будут направлены на распознавание естественного языка. Поэтому я расскажу про работу рекуррентных сетей на примере распознавания эмоций.
Что такое рекуррентные нейронные сети? Это примерно то же самое, что и обычные нейронные сети, но с обратной связью. Обратная связь нам нужна, чтобы передавать на вход нейронной сети или на какой-то из ее слоев предыдущее состояние системы.
Предположим, мы обрабатываем эмоции. Даже в улыбке - одной из самых простых эмоций - есть несколько моментов: от нейтрального выражения лица до того момента, когда у нас будет полная улыбка. Они идут друг за другом последовательно. Чтоб это хорошо понимать, нам нужно уметь наблюдать за тем, как это происходит, передавать то, что было на предыдущем кадре в следующий шаг работы системы.

В 2005 году на состязании Emotion Recognition in the Wild специально для распознавания эмоций команда из Монреаля представила рекуррентную систему, которая выглядела очень просто. У нее было всего несколько свёрточных слоев, и она работала исключительно с видео. В этом году они добавили также распознавание аудио и cагрегировали покадровые данные, которые получаются из convolutional neural networks, данные аудиосигнала с работой рекуррентной нейронной сети (с возвратом состояния) и получили первое место на состязании.
Обучение с подкреплением
Следующий тип нейронных сетей, который очень часто используется в последнее время, но не получил такой широкой огласки, как предыдущие 2 типа - это deep reinforcement learning, обучение с подкреплением.Дело в том, что в предыдущих двух случаях мы используем базы данных. У нас есть либо данные с лиц, либо данные с картинок, либо данные с эмоциями с видеороликов. Если у нас этого нет, если мы не можем это отснять, как научить робота брать объекты? Это мы делаем автоматически - мы не знаем, как это работает. Другой пример: составлять большие базы данных в компьютерных играх сложно, да и не нужно, можно сделать гораздо проще.
Все, наверное, слышали про успехи deep reinforcement learning в Atari и в го.
Кто слышал про Atari? Ну кто-то слышал, хорошо. Про AlphaGo думаю слышали все, поэтому я даже не буду рассказывать, что конкретно там происходит.

Что происходит в Atari? Слева как раз изображена архитектура этой нейронной сети. Она обучается, играя сама с собой для того, чтобы получить максимальное вознаграждение. Максимальное вознаграждение - это максимально быстрый исход игры с максимально большим счетом.
Справа вверху - последний слой нейронной сети, который изображает всё количество состояний системы, которая играла сама против себя всего лишь в течение двух часов. Красным изображены желательные исходы игры с максимальным вознаграждением, а голубым - нежелательные. Сеть строит некое поле и движется по своим обученным слоям в то состояние, которого ей хочется достичь.
В робототехнике ситуация состоит немного по-другому. Почему? Здесь у нас есть несколько сложностей. Во-первых, у нас не так много баз данных. Во-вторых, нам нужно координировать сразу три системы: восприятие робота, его действия с помощью манипуляторов и его память - то, что было сделано в предыдущем шаге и как это было сделано. В общем это все очень сложно.
Дело в том, что ни одна нейронная сеть, даже deep learning на данный момент, не может справится с этой задачей достаточно эффективно, поэтому deep learning только исключительно кусочки того, что нужно сделать роботам. Например, недавно Сергей Левин предоставил систему, которая учит робота хватать объекты.

Вот здесь показаны опыты, которые он проводил на своих 14 роботах-манипуляторах.
Что здесь происходит? В этих тазиках, которые вы перед собой видите, различные объекты: ручки, ластики, кружки поменьше и побольше, тряпочки, разные текстуры, разной жесткости. Неясно, как научить робота захватывать их. В течение многих часов, а даже, вроде, недель, роботы тренировались, чтобы уметь захватывать эти предметы, составлялись по этому поводу базы данных.
Базы данных - это некий отклик среды, который нам нужно накопить для того, чтобы иметь возможность обучить робота что-то делать в дальнейшем. В дальнейшем роботы будут обучаться на этом множестве состояний системы.
Нестандартные применения нейронных сетей
Это к сожалению, конец, у меня не много времени. Я расскажу про те нестандартные решения, которые сейчас есть и которые, по многим прогнозам, будут иметь некое приложение в будущем.Итак, ученые Стэнфорда недавно придумали очень необычное применение нейронной сети CNN для предсказания бедности. Что они сделали?
На самом деле концепция очень проста. Дело в том, что в Африке уровень бедности зашкаливает за все мыслимые и немыслимые пределы. У них нет даже возможности собирать социальные демографические данные. Поэтому с 2005 года у нас вообще нет никаких данных о том, что там происходит.
Учёные собирали дневные и ночные карты со спутников и скармливали их нейронной сети в течение некоторого времени.
Нейронная сеть была преднастроена на ImageNet"е. То есть первые слои фильтров были настроены так, чтобы она умела распознавать уже какие-то совсем простые вещи, например, крыши домов, для поиска поселения на дневных картах. Затем дневные карты были сопоставлены с картами ночной освещенности того же участка поверхности для того, чтобы сказать, насколько есть деньги у населения, чтобы хотя бы освещать свои дома в течение ночного времени.

Здесь вы видите результаты прогноза, построенного нейронной сетью. Прогноз был сделан с различным разрешением. И вы видите - самый последний кадр - реальные данные, собранные правительством Уганды в 2005 году.
Можно заметить, что нейронная сеть составила достаточно точный прогноз, даже с небольшим сдвигом с 2005 года.
Были конечно и побочные эффекты. Ученые, которые занимаются deep learning, всегда с удивлением обнаруживают разные побочные эффекты. Например, как те, что сеть научилась распознавать воду, леса, крупные строительные объекты, дороги - все это без учителей, без заранее построенных баз данных. Вообще полностью самостоятельно. Были некие слои, которые реагировали, например, на дороги.
И последнее применение о котором я хотела бы поговорить - семантическая сегментация 3D изображений в медицине. Вообще medical imaging - это сложная область, с которой очень сложно работать.
Для этого есть несколько причин.
- У нас очень мало баз данных. Не так легко найти картинку мозга, к тому же повреждённого, и взять ее тоже ниоткуда нельзя.
- Даже если у нас есть такая картинка, нужно взять медика и заставить его вручную размещать все многослойные изображения, что очень долго и крайне неэффективно. Не все медики имеют ресурсы для того, чтобы этим заниматься.
- Нужна очень высокая точность. Медицинская система не может ошибаться. При распознавании, например, котиков, не распознали - ничего страшного. А если мы не распознали опухоль, то это уже не очень хорошо. Здесь особо свирепые требования к надежности системы.
- Изображения в трехмерных элементах - вокселях, не в пикселях, что доставляет дополнительные сложности разработчикам систем.
Где это применяется: определение повреждений после удара, для поиска опухоли в мозгу, в кардиологии для определения того, как работает сердце.

Вот пример для определения объема плаценты.
Автоматически это работает хорошо, но не настолько, чтобы это было выпущено в производство, поэтому пока только начинается. Есть несколько стартапов для создания таких систем медицинского зрения. Вообще в deep learning очень много стартапов в ближайшее время. Говорят, что venture capitalists в последние полгода выделили больше бюджета на стартапы обрасти deep learning, чем за прошедшие 5 лет.
Эта область активно развивается, много интересных направлений. Мы с вами живем в интересное время. Если вы занимаетесь deep learning, то вам, наверное, пора открывать свой стартап.
Ну на этом я, наверное, закруглюсь. Спасибо вам большое.
В первой половине 2016 года мир услышал о множестве разработок в области нейронных сетей - свои алгоритмы демонстрировали Google (сеть-игрок в го AlphaGo), Microsoft (ряд сервисов для идентификации изображений), стартапы MSQRD, Prisma и другие.
В закладки
Редакция сайт рассказывает, что из себя представляют нейронные сети, для чего они нужны, почему захватили планету именно сейчас, а не годами раньше или позже, сколько на них можно заработать и кто является основными игроками рынка. Своими мнениями также поделились эксперты из МФТИ, «Яндекса», Mail.Ru Group и Microsoft.
Что собой представляют нейронные сети и какие задачи они могут решать
Нейронные сети - одно из направлений в разработке систем искусственного интеллекта. Идея заключается в том, чтобы максимально близко смоделировать работу человеческой нервной системы - а именно, её способности к обучению и исправлению ошибок. В этом состоит главная особенность любой нейронной сети - она способна самостоятельно обучаться и действовать на основании предыдущего опыта, с каждым разом делая всё меньше ошибок.
Нейросеть имитирует не только деятельность, но и структуру нервной системы человека. Такая сеть состоит из большого числа отдельных вычислительных элементов («нейронов»). В большинстве случаев каждый «нейрон» относится к определённому слою сети. Входные данные последовательно проходят обработку на всех слоях сети. Параметры каждого «нейрона» могут изменяться в зависимости от результатов, полученных на предыдущих наборах входных данных, изменяя таким образом и порядок работы всей системы.
Руководитель направления «Поиск Mail.ru» в Mail.Ru Group Андрей Калинин отмечает, что нейронные сети способны решать такие же задачи, как и другие алгоритмы машинного обучения, разница заключается лишь в подходе к обучению.
Все задачи, которые могут решать нейронные сети, так или иначе связаны с обучением. Среди основных областей применения нейронных сетей - прогнозирование, принятие решений, распознавание образов, оптимизация, анализ данных.
Директор программ технологического сотрудничества Microsoft в России Влад Шершульский замечает, что сейчас нейросети применяются повсеместно: «Например, многие крупные интернет-сайты используют их, чтобы сделать реакцию на поведение пользователей более естественной и полезной своей аудитории. Нейросети лежат в основе большинства современных систем распознавания и синтеза речи, а также распознавания и обработки изображений. Они применяются в некоторых системах навигации, будь то промышленные роботы или беспилотные автомобили. Алгоритмы на основе нейросетей защищают информационные системы от атак злоумышленников и помогают выявлять незаконный контент в сети».
В ближайшей перспективе (5-10 лет), полагает Шершульский, нейронные сети будут использоваться ещё шире:
Представьте себе сельскохозяйственный комбайн, исполнительные механизмы которого снабжены множеством видеокамер. Он делает пять тысяч снимков в минуту каждого растения в полосе своей траектории и, используя нейросеть, анализирует - не сорняк ли это, не поражено ли оно болезнью или вредителями. И обрабатывает каждое растение индивидуально. Фантастика? Уже не совсем. А через пять лет может стать нормой. - Влад Шершульский, Microsoft
Заведующий лабораторией нейронных систем и глубокого обучения Центра живых систем МФТИ Михаил Бурцев приводит предположительную карту развития нейронных сетей на 2016-2018 годы:
- системы распознавания и классификации объектов на изображениях;
- голосовые интерфейсы взаимодействия для интернета вещей;
- системы мониторинга качества обслуживания в колл-центрах;
- системы выявления неполадок (в том числе, предсказывающие время технического обслуживания), аномалий, кибер-физических угроз;
- системы интеллектуальной безопасности и мониторинга;
- замена ботами части функций операторов колл-центров;
- системы видеоаналитики;
- самообучающиеся системы, оптимизирующие управление материальными потоками или расположение объектов (на складах, транспорте);
- интеллектуальные, самообучающиеся системы управления производственными процессами и устройствами (в том числе, робототехнические);
- появление систем универсального перевода «на лету» для конференций и персонального использования;
- появление ботов-консультантов технической поддержки или персональных ассистентов, по функциям близким к человеку.
Директор по распространению технологий «Яндекса» Григорий Бакунов считает, что основой для распространения нейросетей в ближайшие пять лет станет способность таких систем к принятию различных решений: «Главное, что сейчас делают нейронные сети для человека, - избавляют его от излишнего принятия решений. Так что их можно использовать практически везде, где принимаются не слишком интеллектуальные решения живым человеком. В следующие пять лет будет эксплуатироваться именно этот навык, который заменит принятие решений человеком на простой автомат».
Почему нейронные сети стали так популярны именно сейчас
Учёные занимаются разработкой искусственных нейронных сетей более 70 лет. Первую попытку формализовать нейронную сеть относят к 1943 году, когда два американских учёных (Уоррен Мак-Каллок и Уолтер Питтс) представили статью о логическом исчислении человеческих идей и нервной активности.
Однако до недавнего времени, говорит Андрей Калинин из Mail.Ru Group, скорость работы нейросетей была слишком низкой, чтобы они могли получить широкое распространение, и поэтому такие системы в основном использовались в разработках, связанных с компьютерным зрением, а в остальных областях применялись другие алгоритмы машинного обучения.
Трудоёмкая и длительная часть процесса разработки нейронной сети - её обучение. Для того, чтобы нейронная сеть могла корректно решать поставленные задачи, требуется «прогнать» её работу на десятках миллионов наборов входных данных. Именно с появлением различных технологий ускоренного обучения и связывают распространение нейросетей Андрей Калинин и Григорий Бакунов.
Главное, что произошло сейчас, - появились разные уловки, которые позволяют делать нейронные сети, значительно меньше подверженные переобучению.- Григорий Бакунов, «Яндекс»
«Во-первых, появился большой и общедоступный массив размеченных картинок (ImageNet), на которых можно обучаться. Во-вторых, современные видеокарты позволяют в сотни раз быстрее обучать нейросети и их использовать. В-третьих, появились готовые, предобученные нейросети, распознающие образы, на основании которых можно делать свои приложения, не занимаясь длительной подготовкой нейросети к работе. Всё это обеспечивает очень мощное развитие нейросетей именно в области распознавания образов», - замечает Калинин.
Каковы объёмы рынка нейронных сетей
«Очень легко посчитать. Можно взять любую область, в которой используется низкоквалифицированный труд, - например, работу операторов колл-центров - и просто вычесть все людские ресурсы. Я бы сказал, что речь идет о многомиллиардном рынке даже в рамках отдельной страны. Какое количество людей в мире задействовано на низкоквалифицированной работе, можно легко понять. Так что даже очень абстрактно говоря, думаю, речь идет о стомиллиардном рынке во всем мире», - говорит директор по распространению технологий «Яндекса» Григорий Бакунов.
По некоторым оценкам, больше половины профессий будет автоматизировано – это и есть максимальный объём, на который может быть увеличен рынок алгоритмов машинного обучения (и нейронных сетей в частности).- Андрей Калинин, Mail.Ru Group
«Алгоритмы машинного обучения - это следующий шаг в автоматизации любых процессов, в разработке любого программного обеспечения. Поэтому рынок как минимум совпадает со всем рынком ПО, а, скорее, превосходит его, потому что становится возможно делать новые интеллектуальные решения, недоступные старому ПО», - продолжает руководитель направления «Поиск Mail.ru» в Mail.Ru Group Андрей Калинин.
Зачем разработчики нейронных сетей создают мобильные приложения для массового рынка
В последние несколько месяцев на рынке появилось сразу несколько громких развлекательных проектов, использующих нейронные сети - это и популярный видеосервис , который социальная сеть Facebook, и российские приложения для обработки снимков (в июне инвестиции от Mail.Ru Group) и и другие.
Способности собственных нейронных сетей демонстрировали и Google (технология AlphaGo выиграла у чемпиона в го; в марте 2016 года корпорация продала на аукционе 29 картин, нарисованных нейросетями и так далее), и Microsoft (проект CaptionBot , распознающий изображения на снимках и автоматически генерирующий подписи к ним; проект WhatDog , по фотографии определяющий породу собаки; сервис HowOld , определяющий возраст человека на снимке и так далее), и «Яндекс» (в июне команда встроила в приложение «Авто.ру» сервис для распознавания автомобилей на снимках; представила записанный нейросетями музыкальный альбом; в мае создала проект LikeMo.net для рисования в стиле известных художников).
Такие развлекательные сервисы создаются скорее не для решения глобальных задач, на которые и нацелены нейросети, а для демонстрации способностей нейронной сети и проведения её обучения.
«Игры - характерная особенность нашего поведения как биологического вида. С одной стороны, на игровых ситуациях можно смоделировать практически все типичные сценарии человеческого поведения, а с другой - и создатели игр и, особенно, игроки могут получить от процесса массу удовольствия. Есть и сугубо утилитарный аспект. Хорошо спроектированная игра приносит не только удовлетворение игрокам: в процессе игры они обучают нейросетевой алгоритм. Ведь в основе нейросетей как раз и лежит обучение на примерах», - говорит Влад Шершульский из Microsoft.
«В первую очередь это делается для того, чтобы показать возможности технологии. Другой причины, на самом деле, нет. Если речь идёт о Prisma, то понятно, для чего это делали они. Ребята построили некоторый пайплайн, который позволяет им работать с картинками. Для демонстрации этого они избрали для себя довольно простой способ создания стилизаций. Почему бы и нет? Это просто демонстрация работы алгоритмов», - говорит Григорий Бакунов из «Яндекса».
Другого мнения придерживается Андрей Калинин из Mail.Ru Group: «Конечно, это эффектно с точки зрения публики. С другой стороны, я бы не сказал, что развлекательные продукты не могут быть применены в более полезных областях. Например, задача по стилизации образов крайне актуальна для целого ряда индустрий (дизайн, компьютерные игры, мультипликация - вот лишь несколько примеров), и полноценное использование нейросетей может существенно оптимизировать стоимость и методы создания контента для них».
Основные игроки на рынке нейронных сетей
Как отмечает Андрей Калинин, по большому счёту, большинство присутствующих на рынке нейронных сетей мало чем отличаются друг от друга. «Технологии у всех примерно одинаковые. Но применение нейросетей - это удовольствие, которое могут позволить себе далеко не все. Чтобы самостоятельно обучить нейронную сеть и поставить на ней много экспериментов, нужны большие обучающие множества и парк машин с дорогими видеокартами. Очевидно, что такие возможности есть у крупных компаний», - говорит он.
Среди основных игроков рынка Калинин упоминает Google и её подразделение Google DeepMind, создавшее сеть AlphaGo, и Google Brain. Собственные разработки в этой области есть у Microsoft - ими занимается лаборатория Microsoft Research. Созданием нейронных сетей занимаются в IBM, Facebook (подразделение Facebook AI Research), Baidu (Baidu Institute of Deep Learning) и другие. Множество разработок ведётся в технических университетах по всему миру.
Директор по распространению технологий «Яндекса» Григорий Бакунов отмечает, что интересные разработки в области нейронных сетей встречаются и среди стартапов. «Я бы вспомнил, например, компанию ClarifAI . Это небольшой стартап, сделанный когда-то выходцами из Google. Сейчас они, пожалуй, лучше всех в мире умеют определять содержимое картинки». К таким стартапам относятся и MSQRD, и Prisma, и другие.
В России разработками в области нейронных сетей занимаются не только стартапы, но и крупные технологические компании - например, холдинг Mail.Ru Group применяет нейросети для обработки и классификации текстов в «Поиске», анализа изображений. Компания также ведёт экспериментальные разработки, связанные с ботами и диалоговыми системами.
Созданием собственных нейросетей занимается и «Яндекс»: «В основном такие сети уже используются в работе с изображениями, со звуком, но мы исследуем их возможности и в других областях. Сейчас мы много экспериментов ставим в использовании нейросетей в работе с текстом». Разработки ведутся в университетах: в «Сколтехе», МФТИ, МГУ, ВШЭ и других.
Решение задачи классификации является одним из важнейших применений нейронных сетей.
Задача классификации представляет собой задачу отнесения образца к одному из нескольких попарно не пересекающихся множеств. Примером таких задач может быть, например, задача определения кредитоспособности клиента банка, медицинские задачи, в которых необходимо определить, например, исход заболевания, решение задач управления портфелем ценных бумаг (продать купить или "придержать" акции в зависимости от ситуации на рынке), задача определения жизнеспособных и склонных к банкротству фирм.
Цель классификации
При решении задач классификации необходимо отнести имеющиеся статические образцы (характеристики ситуации на рынке, данные медосмотра, информация о клиенте) к определенным классам. Возможно несколько способов представления данных. Наиболее распространенным является способ, при котором образец представляется вектором. Компоненты этого вектора представляют собой различные характеристики образца, которые влияют на принятие решения о том, к какому классу можно отнести данный образец. Например, для медицинских задач в качестве компонентов этого вектора могут быть данные из медицинской карты больного. Таким образом, на основании некоторой информации о примере, необходимо определить, к какому классу его можно отнести. Классификатор таким образом относит объект к одному из классов в соответствии с определенным разбиением N-мерного пространства, которое называется пространством входов, и размерность этого пространства является количеством компонент вектора.
Прежде всего, нужно определить уровень сложности системы. В реальных задачах часто возникает ситуация, когда количество образцов ограничено, что осложняет определение сложности задачи. Возможно выделить три основных уровня сложности. Первый (самый простой) – когда классы можно разделить прямыми линиями (или гиперплоскостями, если пространство входов имеет размерность больше двух) – так называемая линейная разделимость . Во втором случае классы невозможно разделить линиями (плоскостями), но их возможно отделить с помощью более сложного деления – нелинейная разделимость . В третьем случае классы пересекаются и можно говорить только о вероятностной разделимости .
В идеальном варианте после предварительной обработки мы должны получить линейно разделимую задачу, так как после этого значительно упрощается построение классификатора. К сожалению, при решении реальных задач мы имеем ограниченное количество образцов, на основании которых и производится построение классификатора. При этом мы не можем провести такую предобработку данных, при которой будет достигнута линейная разделимость образцов.
Использование нейронных сетей в качестве классификатора
Сети с прямой связью являются универсальным средством аппроксимации функций, что позволяет их использовать в решении задач классификации. Как правило, нейронные сети оказываются наиболее эффективным способом классификации, потому что генерируют фактически большое число регрессионных моделей (которые используются в решении задач классификации статистическими методами).
К сожалению, в применении нейронных сетей в практических задачах возникает ряд проблем. Во-первых, заранее не известно, какой сложности (размера) может потребоваться сеть для достаточно точной реализации отображения. Эта сложность может оказаться чрезмерно высокой, что потребует сложной архитектуры сетей. Так Минский в своей работе "Персептроны" доказал, что простейшие однослойные нейронные сети способны решать только линейно разделимые задачи. Это ограничение преодолимо при использовании многослойных нейронных сетей. В общем виде можно сказать, что в сети с одним скрытым слоем вектор, соответствующий входному образцу, преобразуется скрытым слоем в некоторое новое пространство, которое может иметь другую размерность, а затем гиперплоскости, соответствующие нейронам выходного слоя, разделяют его на классы. Таким образом сеть распознает не только характеристики исходных данных, но и "характеристики характеристик", сформированные скрытым слоем.
Подготовка исходных данных
Для построения классификатора необходимо определить, какие параметры влияют на принятие решения о том, к какому классу принадлежит образец. При этом могут возникнуть две проблемы. Во-первых, если количество параметров мало, то может возникнуть ситуация, при которой один и тот же набор исходных данных соответствует примерам, находящимся в разных классах. Тогда невозможно обучить нейронную сеть, и система не будет корректно работать (невозможно найти минимум, который соответствует такому набору исходных данных). Исходные данные обязательно должны быть непротиворечивы . Для решения этой проблемы необходимо увеличить размерность пространства признаков (количество компонент входного вектора, соответствующего образцу). Но при увеличении размерности пространства признаков может возникнуть ситуация, когда число примеров может стать недостаточным для обучения сети, и она вместо обобщения просто запомнит примеры из обучающей выборки и не сможет корректно функционировать. Таким образом, при определении признаков необходимо найти компромисс с их количеством.
Далее необходимо определить способ представления входных данных для нейронной сети, т.е. определить способ нормирования. Нормировка необходима, поскольку нейронные сети работают с данными, представленными числами в диапазоне 0..1, а исходные данные могут иметь произвольный диапазон или вообще быть нечисловыми данными. При этом возможны различные способы, начиная от простого линейного преобразования в требуемый диапазон и заканчивая многомерным анализом параметров и нелинейной нормировкой в зависимости от влияния параметров друг на друга.
Кодирование выходных значений
Задача классификации при наличии двух классов может быть решена на сети с одним нейроном в выходном слое, который может принимать одно из двух значений 0 или 1, в зависимости от того, к какому классу принадлежит образец. При наличии нескольких классов возникает проблема, связанная с представлением этих данных для выхода сети. Наиболее простым способом представления выходных данных в таком случае является вектор, компоненты которого соответствуют различным номерам классов. При этом i-я компонента вектора соответствует i-му классу. Все остальные компоненты при этом устанавливаются в 0. Тогда, например, второму классу будет соответствовать 1 на 2 выходе сети и 0 на остальных. При интерпретации результата обычно считается, что номер класса определяется номером выхода сети, на котором появилось максимальное значение. Например, если в сети с тремя выходами мы имеем вектор выходных значений (0.2,0.6,0.4), то мы видим, что максимальное значение имеет вторая компонента вектора, значит класс, к которому относится этот пример, – 2. При таком способе кодирования иногда вводится также понятие уверенности сети в том, что пример относится к этому классу. Наиболее простой способ определения уверенности заключается в определении разности между максимальным значением выхода и значением другого выхода, которое является ближайшим к максимальному. Например, для рассмотренного выше примера уверенность сети в том, что пример относится ко второму классу, определится как разность между второй и третьей компонентой вектора и равна 0.6-0.4=0.2. Соответственно чем выше уверенность, тем больше вероятность того, что сеть дала правильный ответ. Этот метод кодирования является самым простым, но не всегда самым оптимальным способом представления данных.
Известны и другие способы. Например, выходной вектор представляет собой номер кластера, записанный в двоичной форме. Тогда при наличии 8 классов нам потребуется вектор из 3 элементов, и, скажем, 3 классу будет соответствовать вектор 011. Но при этом в случае получения неверного значения на одном из выходов мы можем получить неверную классификацию (неверный номер кластера), поэтому имеет смысл увеличить расстояние между двумя кластерами за счет использования кодирования выхода по коду Хемминга, который повысит надежность классификации.
Другой подход состоит в разбиении задачи с k классами на k*(k-1)/2 подзадач с двумя классами (2 на 2 кодирование) каждая. Под подзадачей в данном случае понимается то, что сеть определяет наличие одной из компонент вектора. Т.е. исходный вектор разбивается на группы по два компонента в каждой таким образом, чтобы в них вошли все возможные комбинации компонент выходного вектора. Число этих групп можно определить как количество неупорядоченных выборок по два из исходных компонент. Из комбинаторики
$A_k^n = \frac{k!}{n!\,(k\,-\,n)!} = \frac{k!}{2!\,(k\,-\,2)!} = \frac{k\,(k\,-\,1)}{2}$
Тогда, например, для задачи с четырьмя классами мы имеем 6 выходов (подзадач) распределенных следующим образом:
| N подзадачи(выхода) | КомпонентыВыхода |
|---|---|
| 1 | 1-2 |
| 2 | 1-3 |
| 3 | 1-4 |
| 4 | 2-3 |
| 5 | 2-4 |
| 6 | 3-4 |
Где 1 на выходе говорит о наличии одной из компонент. Тогда мы можем перейти к номеру класса по результату расчета сетью следующим образом: определяем, какие комбинации получили единичное (точнее близкое к единице) значение выхода (т.е. какие подзадачи у нас активировались), и считаем, что номер класса будет тот, который вошел в наибольшее количество активированных подзадач (см. таблицу).
Это кодирование во многих задачах дает лучший результат, чем классический способ кодирование.
Выбор объема сети
Правильный выбор объема сети имеет большое значение. Построить небольшую и качественную модель часто бывает просто невозможно, а большая модель будет просто запоминать примеры из обучающей выборки и не производить аппроксимацию, что, естественно, приведет к некорректной работе классификатора. Существуют два основных подхода к построению сети – конструктивный и деструктивный. При первом из них вначале берется сеть минимального размера, и постепенно увеличивают ее до достижения требуемой точности. При этом на каждом шаге ее заново обучают. Также существует так называемый метод каскадной корреляции, при котором после окончания эпохи происходит корректировка архитектуры сети с целью минимизации ошибки. При деструктивном подходе вначале берется сеть завышенного объема, и затем из нее удаляются узлы и связи, мало влияющие на решение. При этом полезно помнить следующее правило: число примеров в обучающем множестве должно быть больше числа настраиваемых весов . Иначе вместо обобщения сеть просто запомнит данные и утратит способность к классификации – результат будет неопределен для примеров, которые не вошли в обучающую выборку.
Выбор архитектуры сети
При выборе архитектуры сети обычно опробуется несколько конфигураций с различным количеством элементов. При этом основным показателем является объем обучающего множества и обобщающая способность сети. Обычно используется алгоритм обучения Back Propagation (обратного распространения) с подтверждающим множеством.
Алгоритм построения классификатора на основе нейронных сетей
- Работа с данными
- Составить базу данных из примеров, характерных для данной задачи
- Разбить всю совокупность данных на два множества: обучающее и тестовое (возможно разбиение на 3 множества: обучающее, тестовое и подтверждающее).
- Предварительная обработка
- Выбрать систему признаков, характерных для данной задачи, и преобразовать данные соответствующим образом для подачи на вход сети (нормировка, стандартизация и т.д.). В результате желательно получить линейно отделяемое пространство множества образцов.
- Выбрать систему кодирования выходных значений (классическое кодирование, 2 на 2 кодирование и т.д.)
- Конструирование, обучение и оценка качества сети
- Выбрать топологию сети: количество слоев, число нейронов в слоях и т.д.
- Выбрать функцию активации нейронов (например "сигмоида")
- Выбрать алгоритм обучения сети
- Оценить качество работы сети на основе подтверждающего множества или другому критерию, оптимизировать архитектуру (уменьшение весов, прореживание пространства признаков)
- Остановится на варианте сети, который обеспечивает наилучшую способность к обобщению и оценить качество работы по тестовому множеству
- Использование и диагностика
- Выяснить степень влияния различных факторов на принимаемое решение (эвристический подход).
- Убедится, что сеть дает требуемую точность классификации (число неправильно распознанных примеров мало)
- При необходимости вернутся на этап 2, изменив способ представления образцов или изменив базу данных.
- Практически использовать сеть для решения задачи.
Для того, чтобы построить качественный классификатор, необходимо иметь качественные данные. Никакой из методов построения классификаторов, основанный на нейронных сетях или статистический, никогда не даст классификатор нужного качества, если имеющийся набор примеров не будет достаточно полным и представительным для той задачи, с которой придется работать системе.
Нейронные сети (искусственная нейронная сеть) - это система соединенных и взаимодействующих между собой простых процессоров (искусственных нейронов). Такие процессоры обычно довольно просты (особенно в сравнении с процессорами, используемыми в персональных компьютерах). Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам. И, тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, эти процессоры вместе способны выполнять довольно сложные задачи, поскольку нейронные сети обучаются в процессе работы.
Уже несколько лет подряд разработчики из разных уголков мира демонстрируют нейронные сети, которые либо могут улучшить фотографии, либо нарисовать картинки с нуля. На калифорнийской конференции GTC 2019 группа Research показала нечто поистине удивительное - искусственный интеллект GauGAN, который создает реалистичные пейзажи на основе схематических рисунков. В отличие от всех аналогичных проектов, новинка умеет добавлять тени и отражения даже от мельчайших камней и менять времена года.
Группы исследователей часто экспериментируют с видео контентом при помощи нейросетей. Взять к примеру , которая в конце 2017 года нейронную сеть менять погоду и время суток на видео. Очередной проект подобного рода запустили исследователи из Университета Карнеги-Мелона, создавшие нейросеть для наложения мимики одного человека на лицо другого.
Нейронные сети - класс аналитических методов, построенных на (гипотетических) принципах обучения мыслящим существ и функционированию мозга, которые позволяют прогнозировать значения некоторых сменных в новых наблюдениях на основе результатов других наблюдений (для этих же или других сменных) после прохождения этапа так называемого обучения на имеющихся данных.
Основные понятия о нейронных сетях
Наиболее часто нейронные сети используются для решения следующих задач:
классификация образов - указание на принадлежность входного образа, представленного вектором признаков, одному или нескольким предварительно определенным классам;
кластеризация - классификация образов при отсутствии учебной выборки с метками классов;
прогнозирование - предусмотрение значения y(tn+1) при известной последовательности y(t1), y(t2) ... y(tn);
оптимизация - обнаружение решения, которое удовлетворяет систему ограничений и максимизирует или минимизирует целевую функцию. Память, которая адресуется по смыслу (ассоциативная память) - память, доступная при указании заданного содержания;
управление - расчет такого входного влияния на систему, за который система работает по желательной траектории.
Структурной основой нейронной сети является формальный нейрон. Нейронные сети возникли из попыток воссоздать способность биологических систем учиться, моделируя низкокорневую структуру мозга. Для этого в основу нейросетевой модели ложится элемент, который имитирует в первом приближении свойства биологического нейрона - формальный нейрон(далее просто нейрон). В организме человека нейроны это особые клетки, способны распространять электрохимические сигналы.
Нейрон имеет разветвленную структуру для введения информации (дендриты), ядро и выход, который разветвляется (аксон). Будучи соединенными определенным образом, нейроны образовывают нейронную сеть. Каждый нейрон характеризуется определенным текущим состоянием и имеет группу синапсов - однонаправленных входных связей, соединенных с выходами других нейронов, а также имеет аксон - исходная связь данного нейрона, за которым сигнал (нарушение или торможение) поступает на синапсы следующих нейронов (рис. 8.1).
Рис. 8.1. Структура формального нейрона.
Каждый синапс характеризуется величиной синапсичной связи или его весом wi, что по физическому содержанию эквивалентная электрической проводимости.
Текущее состояние (уровень активации) нейрона определяется, если взвешенная сумма его входов:
![]() (1)
(1)
где множество сигналов, обозначенных x1, x2,..., xn, поступает на вход нейрона, каждый сигнал увеличивается на соответствующий вес w1, w2,...,wn,и формирует уровень его активации - S. Выход нейрона есть функция уровня его активации:
Y=f(S) (2)
При функционировании нейронных сетей выполняется принцип параллельной обработки сигналов. Он достигается путем объединения большого числа нейронов в так называемые пласты и соединения определенным образом нейронов разных пластов, а также, в некоторых конфигурациях, и нейронов одного пласта между собой, причем обработка взаимодействия всех нейронов ведется послойно.
Р ис.
8.2.
Архитектура нейронной сети с n нейронами
во входном и тремя нейронами в исходном
пласте (однослойный персептрон).
ис.
8.2.
Архитектура нейронной сети с n нейронами
во входном и тремя нейронами в исходном
пласте (однослойный персептрон).
В качестве примера простейшей нейронной сети, рассмотрим однослойный перcептрон с n нейронами во входном и тремя нейронами в исходном пласте (рис. 8.2). Когда на n входов поступают какие-то сигналы, они проходят по синапсам на 3 исходные нейрона. Эта система образовывает единый пласт нейронной сети и выдает три исходных сигнала:
Очевидно, что все весовые коэффициенты синапсов одного пласта нейронов можно свести в матрицу wj, каждый элемент которой wij задает величину синапсичной связи i-го нейрона входного и j-го нейрона исходного пласта(3).
 (3)
(3)
Таким образом, процесс, который происходит в нейронной сети, может быть записан в матричной форме:
где x и y - соответственно входной и исходный векторы, f(v) - активационная функция, которая применяется поэлементно к компонентам вектора v.
Выбор структуры нейронной сети осуществляется согласно особенностям и сложности задачи. Для решения некоторых отдельных типов задач уже существуют оптимальные конфигурации. Если же задача не может быть сведена ни к одному из известных типов, разработчику приходится решать сложную проблему синтеза новой конфигурации.
Возможная такая классификация существующих нейросетей:
По типу входной информации:
сети, которые анализируют двоичную информацию;
сети, которые оперируют с действительными числами.
По методу обучения:
сети, которые необходимо научить перед их применением;
сети, которые не нуждаются в предыдущем обучении, способны обучаться самостоятельно в процессе работы.
По характеру распространения информации:
однонаправленные, в которых информация распространяется только в одном направлении от одного пласта к другому;
рекурентные сети, в которых исходный сигнал элемента может снова поступать на этот элемент и другие элементы сети этого или предыдущего пласта как входной сигнал.
По способу преобразования входной информации:
автоассоциативные;
гетероассоциативные.
Развивая дальше вопрос о возможной классификации нейронных сетей, важно отметить существования бинарных и аналоговых сетей. Первые оперируют с двоичными сигналами, и выход каждого нейрона может принимать только два значения: логический нуль ("приостановленное" состояние) и логическая единица ("возбужденное" состояние). Еще одна классификация разделяет нейронные сети на синхронные и асинхронные. В первом случае в каждый момент времени свое состояние изменяет лишь один нейрон. Во второму - состояние изменяется сразу у целой группы нейронов, как правило, во всем пласте.
Сети также можно классифицировать по количеству пластов. На рис. 8.3 представлен двухслойный персептрон, полученный из персептрона на рис. 8.2 путем добавления второго пласта, который состоит из двух нейронов.
Р ис.
8.3. Архитектура нейронной сети с
однонаправленным распространением
сигнала – двухслойный персептрон.
ис.
8.3. Архитектура нейронной сети с
однонаправленным распространением
сигнала – двухслойный персептрон.
Если рассматривать работу нейронных сетей, которые решают задачу классификации образов, то вообще их работа сводится к классификации (обобщения) входных сигналов, которые принадлежат n-мерному гиперпространству, по некоторому числу классов. С математической точки зрения это происходит путем разбивки гиперпространства гиперплоскостями (запись для случая однослойного персептрона)
![]() ,
(5),
,
(5),
где k=1...m – номер класса.
Каждая полученная область является областью определения отдельного класса. Число таких классов для одной нейронной сети персептронного типа не превышает 2m, где m - число выходов сети. Однако не все из них могут быть распределены данной нейронной сетью.