
Управление итогами в 1с 8.3 для чего.
Они имеют ту же задачу — произвести математические или статистические операции над данными выборки. Но имеются и существенные различия:
- Итоги добавляют строки к данным выборки, в то время как группировки сворачивают выборку и строк становится меньше.
- Итоги можно рассчитывать по всем данным выборки или по отдельным полям, при этом, в отличие от группировок, могут оставаться поля, которые не являются ни итоговыми, ни группировочными.
- Итоги могут учитывать иерархию.
Для начала немного теории. Секция итогов в запросах 1С состоит из двух разделов.
Первый начинается с ключевого слова ИТОГИ и содержит итоговые поля с применяемой к ним агрегатной функцией. Этот раздел может оставаться пустым, тогда в результате запроса получится просто группировка по полям следующего раздела без подсчета итоговых данных.
Существует 6 видов агрегатных функций, применяемых при группировках:
- СУММА — суммирует значения группируемого столбца, применяется только для числовых значений.
- СРЕДНЕЕ — вычисляет среднее арифметическое из значений группируемого столбца, применяется только для числовых значений.
- МАКСИМУМ — может применяться для любых типов значений группируемого столбца, при этом возвращается максимальное значение из всех группируемых. Если значения не числовые, то возвращается последнее при сортировке по возрастанию.
- МИНИМУМ — может применяться для любых типов значений группируемого столбца, при этом возвращается минимальное значение из всех группируемых. Если значения не числовые, то возвращается первое при сортировке по возрастанию.
- КОЛИЧЕСТВО — возвращает количество значений в группируемом столбце, может использоваться для любых типов значений. В расчет не берутся значения типа NULL.
- КОЛИЧЕСТВО РАЗЛИЧНЫЕ — возвращает количество различных значений в группируемом столбце, может использоваться для любых типов значений. В расчет не берутся значения типа NULL.
Второй раздел начинается с ключевого слова ПО и содержит группировочные поля в разрезе которых будет подсчитываться результат по итоговым полям. И/или слово ОБЩИЕ , если нужно подсчитать итоги по всей выборке. Здесь важен порядок, в котором будут располагаться поля, это этого зависит и порядок подсчета итогов в результате запроса.
Если в группировочном поле находятся данные, имеющие иерархическую структуру (иерархический справочник), то можно подсчитать итоги по всей иерархической цепочке. Для этого используется ключевое слово ИЕРАРХИЯ после имени группировочного поля. Если же итоги нужно подсчитывать по всей иерархической цепочке, кроме самого группировочного поля, то используется ключевое слово ТОЛЬКО ИЕРАРХИЯ .
Рассмотрим в качестве примера таблицу поставок товаров.
Задача 1. Подсчет итогов по нескольким полям.
Необходимо узнать, сколько всего товаров поставлено и сколько столов и стульев.
Запрос.
Текст=
"ВЫБРАТЬ
Поставки.Товар КАК Товар,
ИЗ
Поставки КАК Поставки
ИТОГИ
СУММА(Количество)
ПО
ОБЩИЕ,
Товар"
;
В результате получим следующую таблицу с итогами (итоговые строки выделены желтым).
Задача 2. Группировка записей по полю.
Необходимо сгруппировать записи таблицы по виду товара.
Запрос.
Текст=
"ВЫБРАТЬ
Поставки.Товар КАК Товар,
Поставки.Поставщик КАК Поставщик,
Поставки.Количество КАК Количество,
ИЗ
Поставки КАК Поставки
ИТОГИ
ПО
Товар"
;

Задача 3. Подсчет итогов по полю с учетом иерархии.
Запрос.
Текст=
"ВЫБРАТЬ
Поставки.Товар КАК Товар,
Поставки.Поставщик КАК Поставщик,
Поставки.Количество КАК Количество,
ИЗ
Поставки КАК Поставки
ИТОГИ
СУММА(Количество)
ПО
Поставщик ИЕРАРХИЯ"
;
В результате получим следующую таблицу.
Задача 4. Подсчет итогов только по иерархии.
Запрос.
Текст=
"ВЫБРАТЬ
Поставки.Товар КАК Товар,
Поставки.Поставщик КАК Поставщик,
Поставки.Количество КАК Количество,
ИЗ
Поставки КАК Поставки
ИТОГИ
СУММА(Количество)
ПО
Поставщик ТОЛЬКО ИЕРАРХИЯ"
;
В результате получим следующую таблицу.

Как обойти результат запроса с итогами
Результат запроса с итогами можно обойти несколькими способами:
- Как обычный запрос. В этом случае будут последовательно выведены группировочные и детальные записи. Пример такого обхода приведен в статье .
- Отдельно обойти группировки и детальные записи.
В качестве примера возьмем запрос из задачи 1. Но не будем учитывать общие итоги.ГруппировкиТовар = Запрос. Выполнить() . Выбрать(ОбходРезультатаЗапроса. ПоГруппировкам, "Товар" ) ;
Пока ГруппировкиТовар. Следующий() Цикл
//здесь обрабатываем группировочные строки результата запроса
ДетальныеЗаписи = ГруппировкиТовар. Выбрать() ;
Пока ДетальныеЗаписи. Следующий() Цикл
//здесь обрабатываем строки детальных записей, принадлежащих группировкам
КонецЦикла ;
КонецЦикла ;
) а разработчики платформы тут не причем, это довольно известное архитектурное решение, не удалять "нулевые" записи. Я бы даже сказал что это давняя "священная война".
Тут самое главное понять что запись с нулевым количеством в итоге, совершенно не означает что эта запись не нужна.
При проектировании реляционных СУБД считается (считалось) что операции CRUD (Create, Read, Update, Delete) по затратам ресурсов распределяются следующим образом
1. Легкие: Read, Update
2. Средние: Create
3. Тяжелая: Delete
И исходя из логики поведения объекта Регистр, который меняется часто; и из-за больших затрат на удаление записей, существует позиция что:
запись итога не имеет смысла удалять синхронно в момент возникновения нулевого итога, потому что "ноль" не означает "NULL" и потому что велика вероятность того что следующая транзакция "захочет" увеличить или уменьшить итог и он станет ненулевым и нам необходимо будет понести затраты еще и на операцию вставки.
отсюда и посыл, что записи с нулевым итогом имеет смысл удалять асинхронно, то есть в определенный момент времени - но опять же неизвестно как определить этот самый "определенный момент". Такое определение должно лежать на ответственных за приложение - чаще всего как мы знаем пересчет итогов возникает в один момент времени при закрытии периодов учета и подается как некая подготовительная процедура. Вот тут и кроется проблема о которой давно известно - бизнес-задача Закрытие периода не является задачей обеспечения технической стабильности и бизнес иногда может на неё "забить".
У меня в практике была таблица с 400 миллионами записей с нулевым итогом.
И вот тут я могу сказать что разработчики платформы слегка "недочлись" (от слова "недочет") - дело в том что согласно вышеописанному архитектурному решению явно становится понятно, что:
Удалять записи с нулевым итогом нужно по тем ключам (комплектам измерений), по которым длительное время не было операций UPDATE. А этого функционала в платформе нет - есть только глобальный пересчет. В крупных конторах это решается SQL Job"ом выполняющем примерно следующую работу:
1. найти 1 комплект ключей (измерений) по которому не было движений за последний месяц и которые на данный момент нулевые
2. по данному комплекту измерений удалить запись из таблицы итогов
обычно данный Job запускается раз в 10 секунд, выбирается TOP 1 чтобы уменьшить время блокировки на затратную операцию удаления. Естественно в такие базы уже встроены и планы обслуживания по пересчету статистики и перестроению дефрагментированных индексов. В случаях когда таких "ненужных" записей очень много - то обычно уменьшают период запуска Job, либо отказываются от Регистра Итогов - потому что если у вас много ключей уходит в "ноль" и больше не используется, скорее всего у вас по данным ключам 2 операции движения "пришел" и "ушел" - зачем хранить такую информацию в регистре итогов совершенно не ясно.
Ну и про статистику тут тоже все изъезжено - масcовые операции CREATE И DELETE, а также UPDATE ключевого столбца ведут к нарушению дерева поиска по индексу (диапазона распределений ключа по страницам данных) - ну то есть в поисковом диапазоне 1..10 вполне себе может оказаться ключ со значением 23 - так SQL было удобней, потому страница данных была рядом со страницей ключа 7, а ключ 6 заместо которого встал ключ 23 окажется в диапазоне 100..134 - что тоже было удобней исходя из страниц данных. Пример на пальцах - но думаю суть отражает.
Вообще про статистику в момент массовых операций удобно понять следующее: когда вы делается массовую вставку данных SQL пытается вам помочь и оперирует близостью страниц данных для оптимизации вставки и совершенно забывает про оптимизацию операций чтения, где параметром является статистика (диапазоны поиска ключа в таблице - распределение ключа), поэтому чтобы после массовых вставок операции чтения были тоже быстрыми - необходимо восстановить работоспособность инструмента оптимизации чтения выполнив UPDATE STATS.
Да и еще забыл сказать - массовое удаление ведет к массовому возникновению фантомных записей: запись числится удаленной но место занимает - такая ситуация ведет к снижению производительности операций выборок типа SCAN (просмотр).
Anikrion; Albert_2008; Niberu; ser6702; MarchTomCat; olezhe; user598655_ilia-bers; klaus38; LordKim; lmnlmn; spenser123; Monte Carlo; acanta; zaharknyaz; Aggressorak; vesd; Ilya$n; Waanneek; SkyJack; letarch; aegoncharov; user777757; [email protected]; mytg; Gang031; ice-net; Goga1979; ChessCat; RegrZ; 1cprogr_nsk; Irwin; Paradise.87; KAV2; корум; Roman100; for_questions; ragimi; EugeneMIPT; kai nk; kitaevay; crosby; Noxie41; Alex_grem; nixel; new_user; tdml; NeviD; RimidalV; reboot; denis_aka_wolf; Flashill; marchenko.y; freya-khv; asg.aleks; denis13; adm134; TIS_08; mtv:); soulsteps; shalimski; Anesk; pisarevEV; Silenser; kwazi; engineer74; vadimlp77; Артано; dgolovanov; pchela751; aexeel; artbear; jif; Dmitryiv; Rego1337h; slavap; WizaXxX; IvanBoychuk123; fishca; Evil Beaver; Dach; RodinMax; sanches; mdmdvd; zakakvo; Krio2; jacksonp; adeich; afedor; MaximStav; DoctorRoza; Serg0FFan; sanfoto; kinazarov; Bukaska; theshadowco; oitnur; JesteR; detec; audion; laeg; morok1983; krv2k; Di-dog; sparklemal; awa; KAPACEB.AA; Chif13; sa1m0nn; CratosX; AllexSoft; galich; vlad.frost; igorynets; tormozit; vasiliy_b; vladir; meuses; Poopkeen; Andreynikus; Prad2002; dicwork; JohnyDeath; An-Aleksey; It-developer; rgrisha; Bronislav; 7o2uYXg; HolodZar; адуырщдв; AzagTot; Рамзес; DenisCh; PONOM; rеd80; w-divin; metmetmet; CheBurator; PressaLod; Diversus; sevushka; Aleksey.Bochkov; yuraos;
В этой статье мы рассмотрим данную системную утилиту «Тестирование и исправление информационной базы» в 1С 8.3 и особенности её использования.
Перед проведением любых операций необходимо !
Тестирование и исправление информационной базы 1С
Режим тестирования и исправления вызывается в конфигураторе системы 1С 8.3 выбором меню Администрирование — Тестирование и исправление.
Проверки и режимы
В этом окне указывается список необходимых проверок и режимов, которые будут произведены в результате работы утилиты. Рассмотрим каждую галочку подробнее:
Получите 267 видеоуроков по 1С бесплатно:
- Реиндексация таблиц информационной базы — если установлен этот флаг, будет произведена реиндексация таблиц. Реиндексация — полное перестроение индексов для заданных таблиц. Реиндексация существенно повышает производительность системы в целом. Данная процедура никогда не будет лишней и увеличивает производительность системы.
- Проверка логической целостности информационной базы — система умеет проверять логическую и структурную целостность базы данных, находить ошибки в организации данных (например, страниц в файле).
- Проверка ссылочной целостности информационной базы — подпункт логической проверки, проверяет информацию в базе данных на наличие «битых» ссылок. «Битые» ссылки появляются в базе из-за некорректной обработки информации разработчиком, чаще всего при непосредственном удалении данных или неправильно настроенном обмене данных. При нахождении ошибок можно выбрать 3 варианта действий: Создавать объекты — система создает элементы-заглушки, которые можно потом заполнить необходимой информацией, Очищать ссылки — «битые» ссылки будут очищены, Не изменять — система только покажет Вам ошибки.
- Пересчет итогов — в платформе 1С в и есть понятие итогов. Итоги — таблица подсчитанных результатов, данные из которой получить быстрее, чем анализировать весь регистр сведений. Как правило, пересчет итогов увеличивает производительность системы.
- Сжатие таблиц информационной базы — если установлен этот флаг, будет сжата и уменьшится в объеме. Связанно это с тем, что при удалении данных из базы данных, 1С не удаляет физически эти объекты, а лишь «помечает» их на удаление. Т.е. пользователь не видит их, а они есть:). Вот именно сжатие базы данных и удаляет такие записи окончательно. Также такого эффекта можно достичь выгрузкой и загрузкой файла базы данных (*.dt).
- Реструктуризация таблиц информационной базы — процесс, с помощью которого система осуществляет пересоздание таблиц баз данных, обычно эта процедура вызывается при внесения изменений в структуру метаданных конфигурации. Реструктуризация всей БД — процесс долгий, будьте внимательны.
Если по каким-то причинам тестирование и исправление не помогает или у вас нет доступа в конфигуратор, воспользуйтесь утилитой .
Продолжаем изучать программирование в системе 1С Предприятие. Сегодня поговорим о том, как подсчитать итоги по колонке в табличной части. Нам нужно чтобы итог подсчитывался автоматически.
Автоподсчёт итогов по колонке в табличной части 1С
И так преступим, запускаем 1С в режиме конфигуратора. Далее переходим в созданный ранее документ. Открываем его и переходим на вкладку формы и открываем её.
В окне формы нужно кликнуть два раза на табличную часть справа должно появиться окно свойств таблицы. В нем ищем пункт Подвал и ставим галочку.

После чего на форме в табличной части снизу должен появиться подвал.

Теперь на нужно чтобы в колонке Сумма подсчитывался итого. Для этого на вкладке Элементы ищем пункт с Название МатериалыСумма и кликаем на нем два раза. Справа появиться свойства поля в них ищем пункт
ТекстПодвала и вписываем Итого. А в пункте ПутьКДаннымПОдвала кликаем на три точечки.
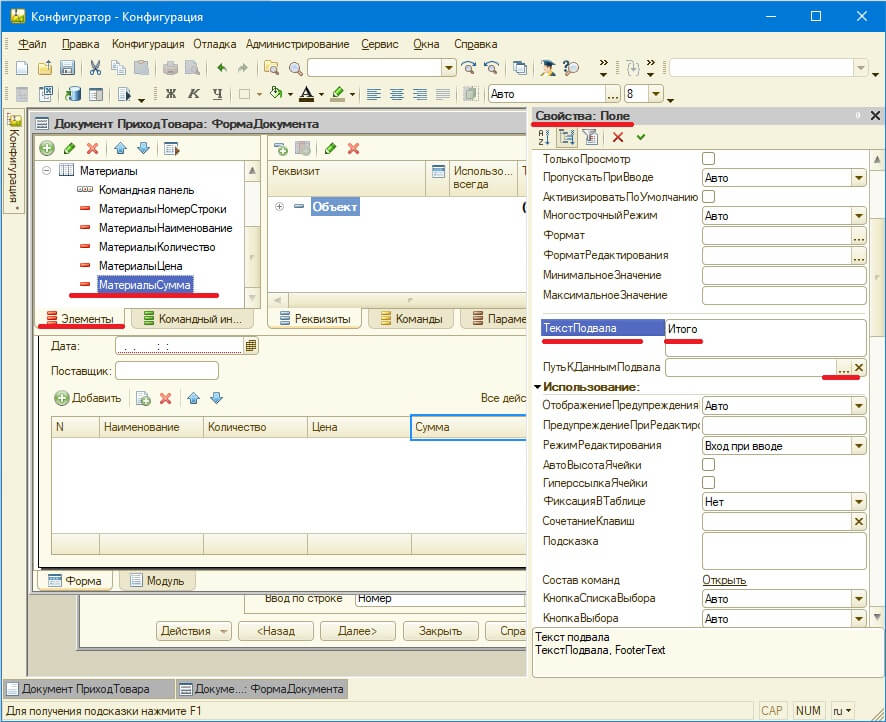
В открывшемся окне нужно выбрать ИтогоСумма.

Теперь запускаем отладку и проверяем считается ли итог по колонке в табличной части документа.
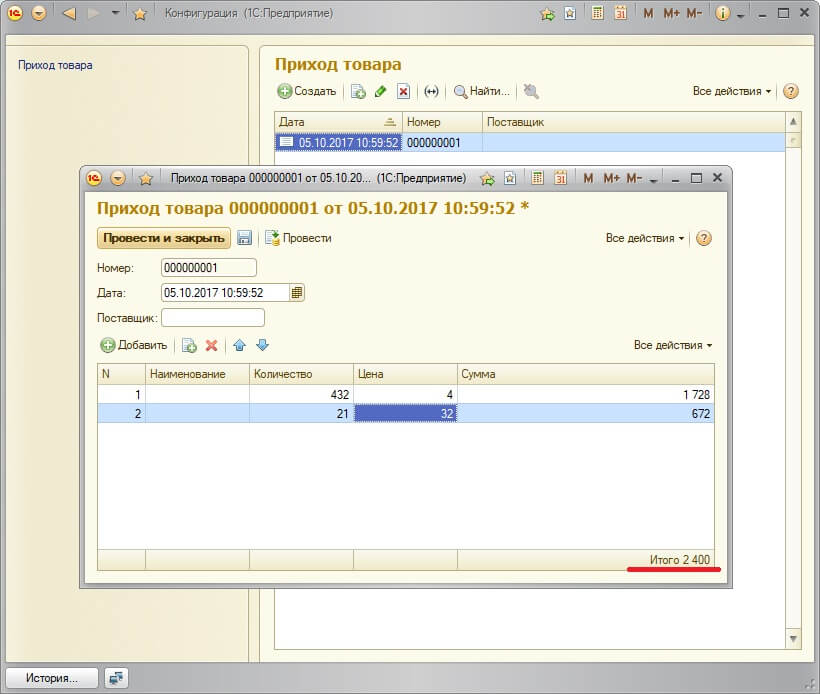
Вот мы и сделали автоматический подсчет итогов по колонке. Таким образом можно подсчитать итого во всех колонках и в любых документах.